Abstract
Graphical Abstract
❭ In this class, taught by Dr. Crowthers, we focus on scientific research and engineering. During the first part of the year, we conduct independent research projects that incorporate reviewing literature, making conjectures, developing methodology, designing experiments, and communicating findings. Our final projects are presented at a school-wide science fair, with the possibility for advancement to regional, state, and international fairs.█
Armaan Priyadarshan
Advisor: Dr. Kevin Crowthers, Ph.D.
The overall aim of this project is to investigate the impact of data preparation techniques and overall dataset quality on the performance of Large Language Models (LLMs). Within this project, the effect of the dataset on the model will be evaluated and is expected to have a direct correlation to performance.
LLMs and datasets are growing in size, and there is a need for automated methods of ensuring data quality
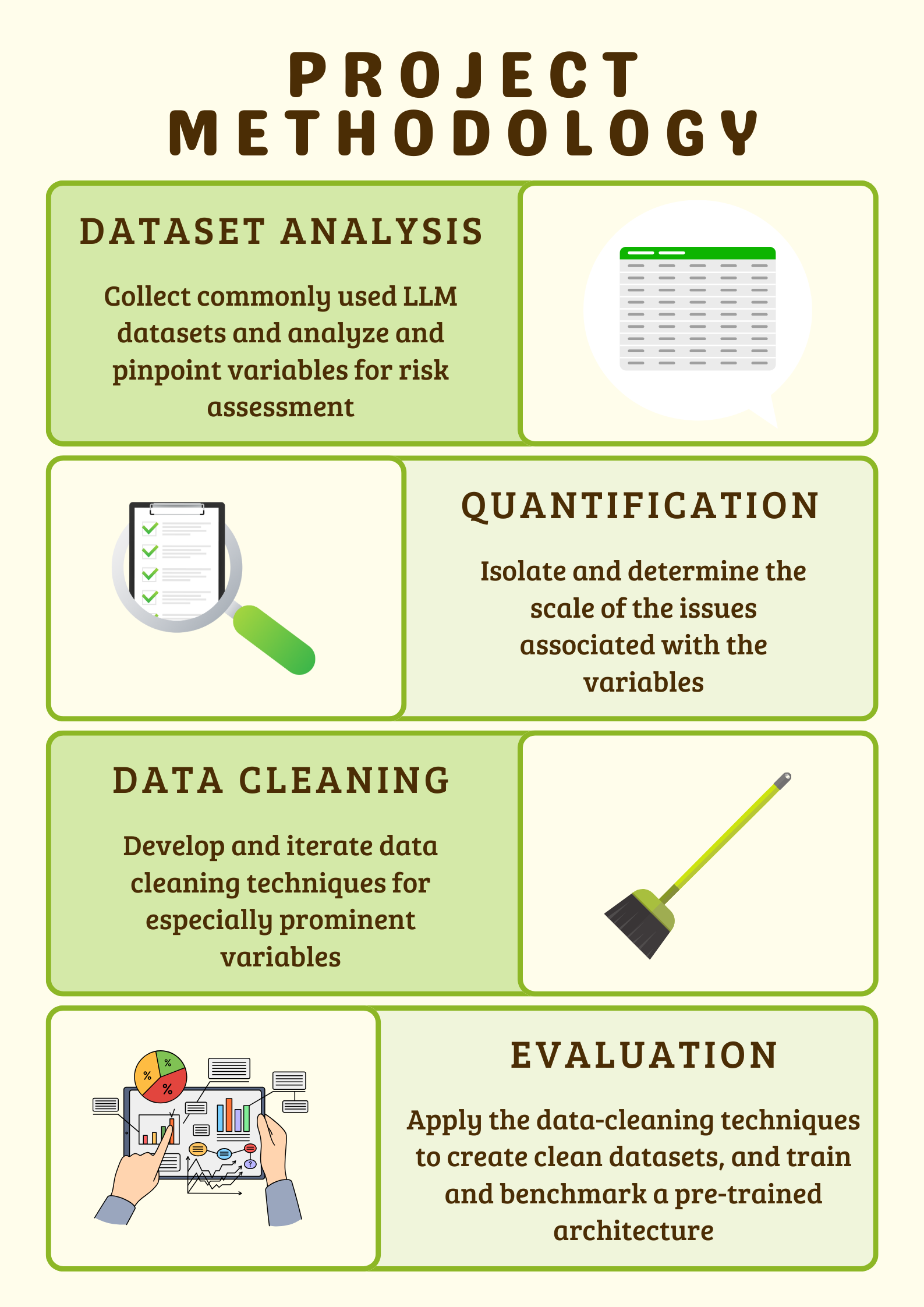
Data preparation techniques for LLM datasets will be developed and evaluated through their impact on existing datasets and resultant language models
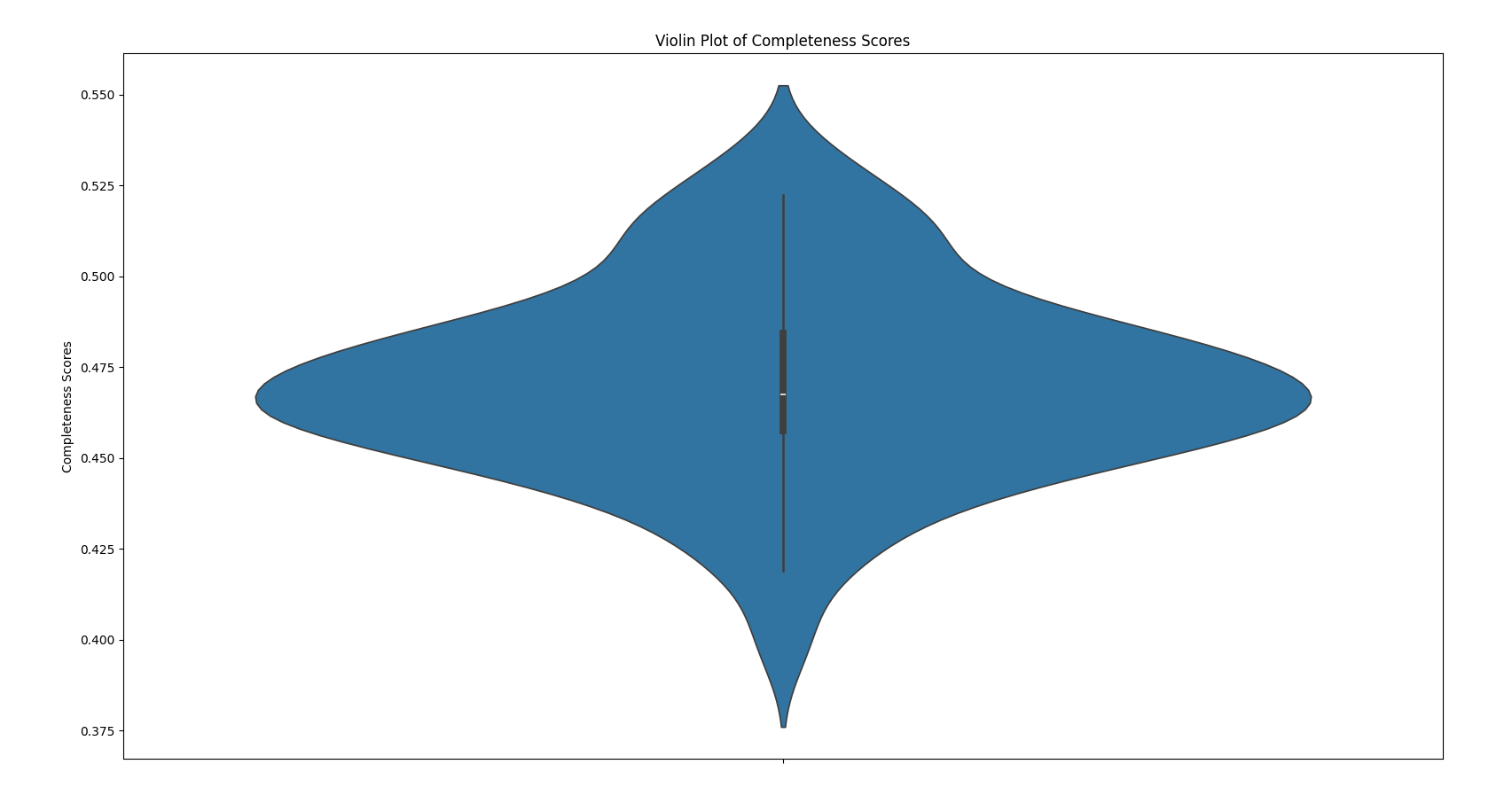
A violin plot of completeness scores of the first 100 training examples in the C4 dataset as evaluated by the BERT model and tokenizer for sequence classification
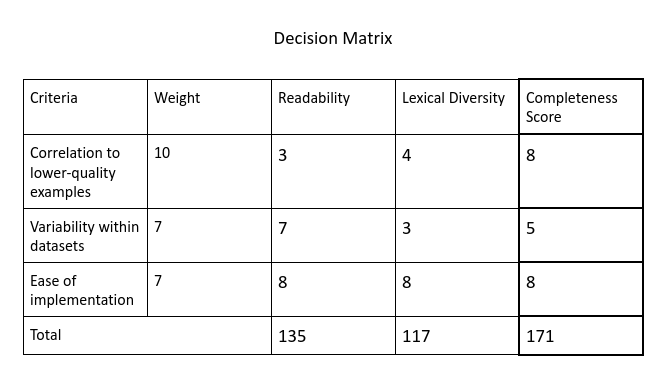
A decision matrix for determining which risk assessment variable to target in the data cleaning algorithm

The difference in the reported perplexity of the model trained on raw data versus the model trained on cleaned data
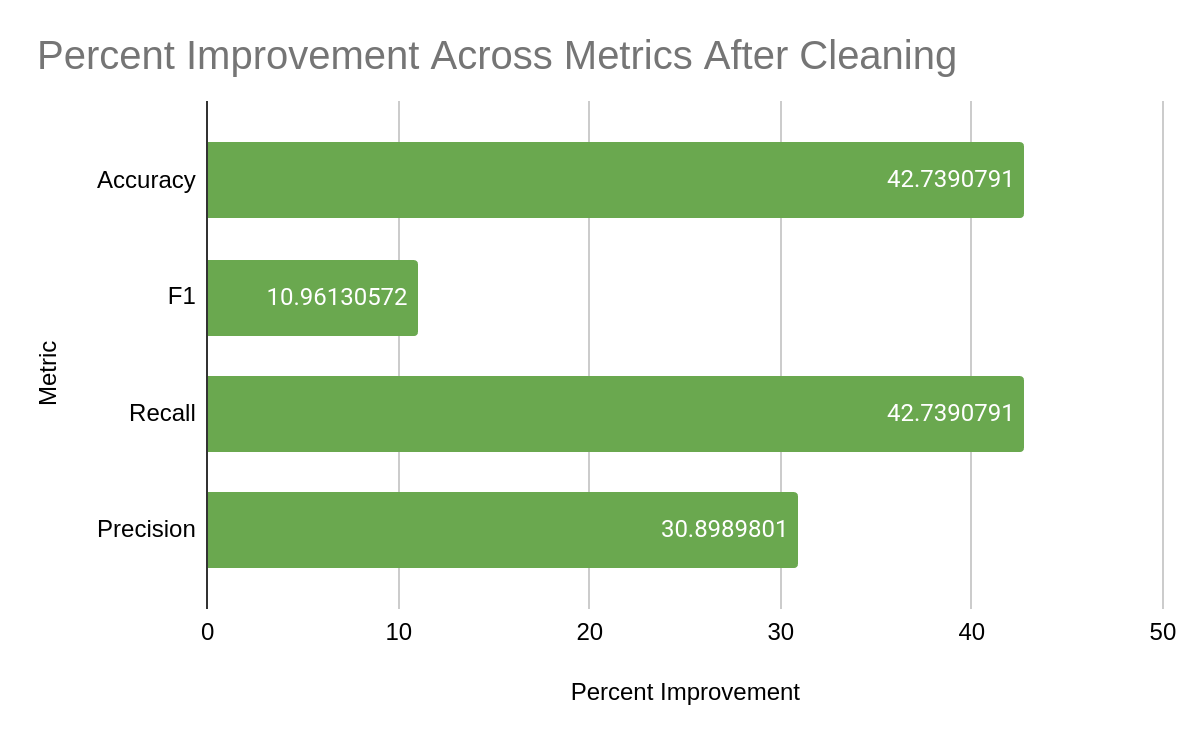
The difference in accuracy, F1, recall, and precision of the model trained on raw data versus the model trained on clean data