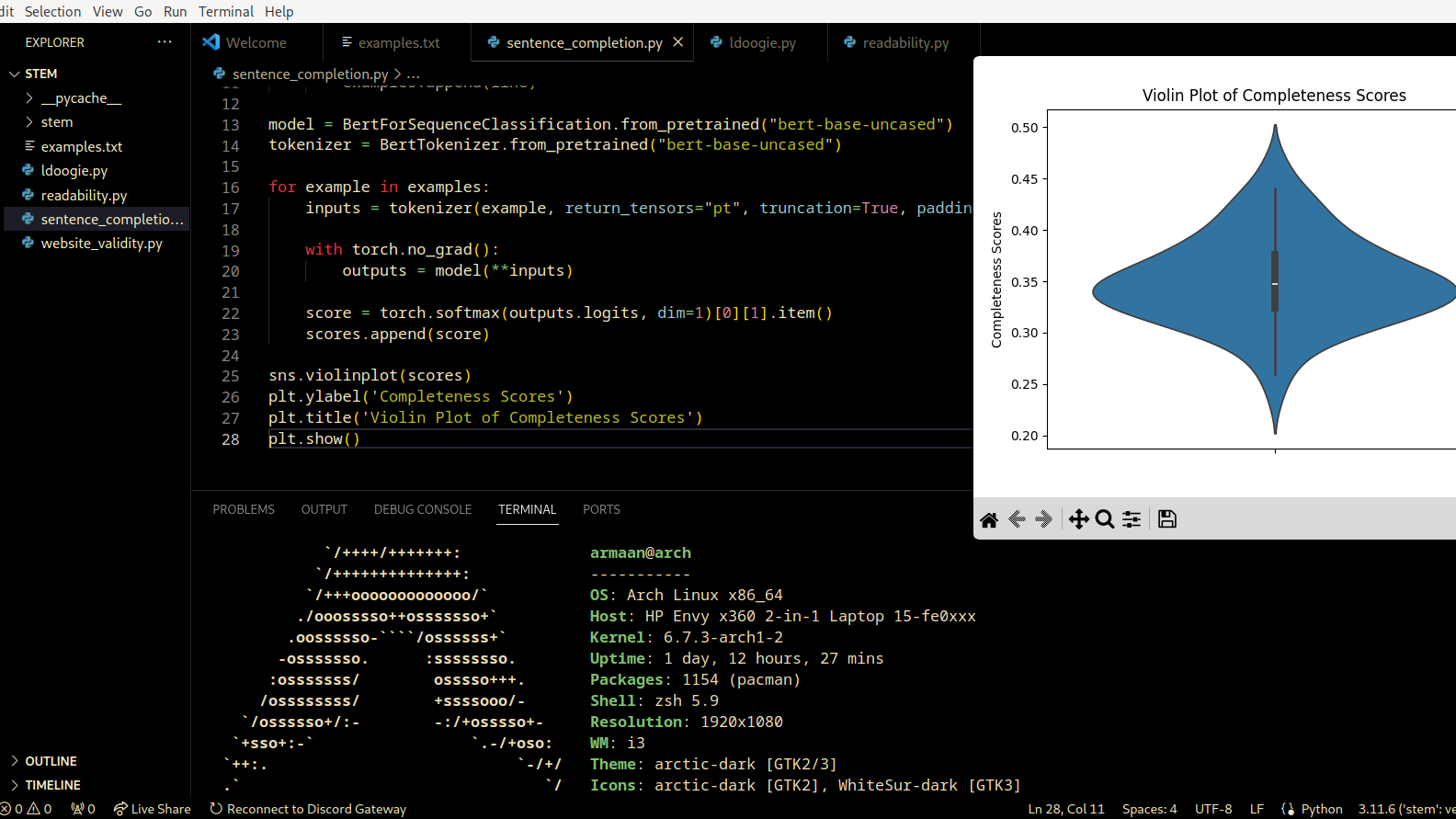
Preliminary dataset analysis conducted in VSCode
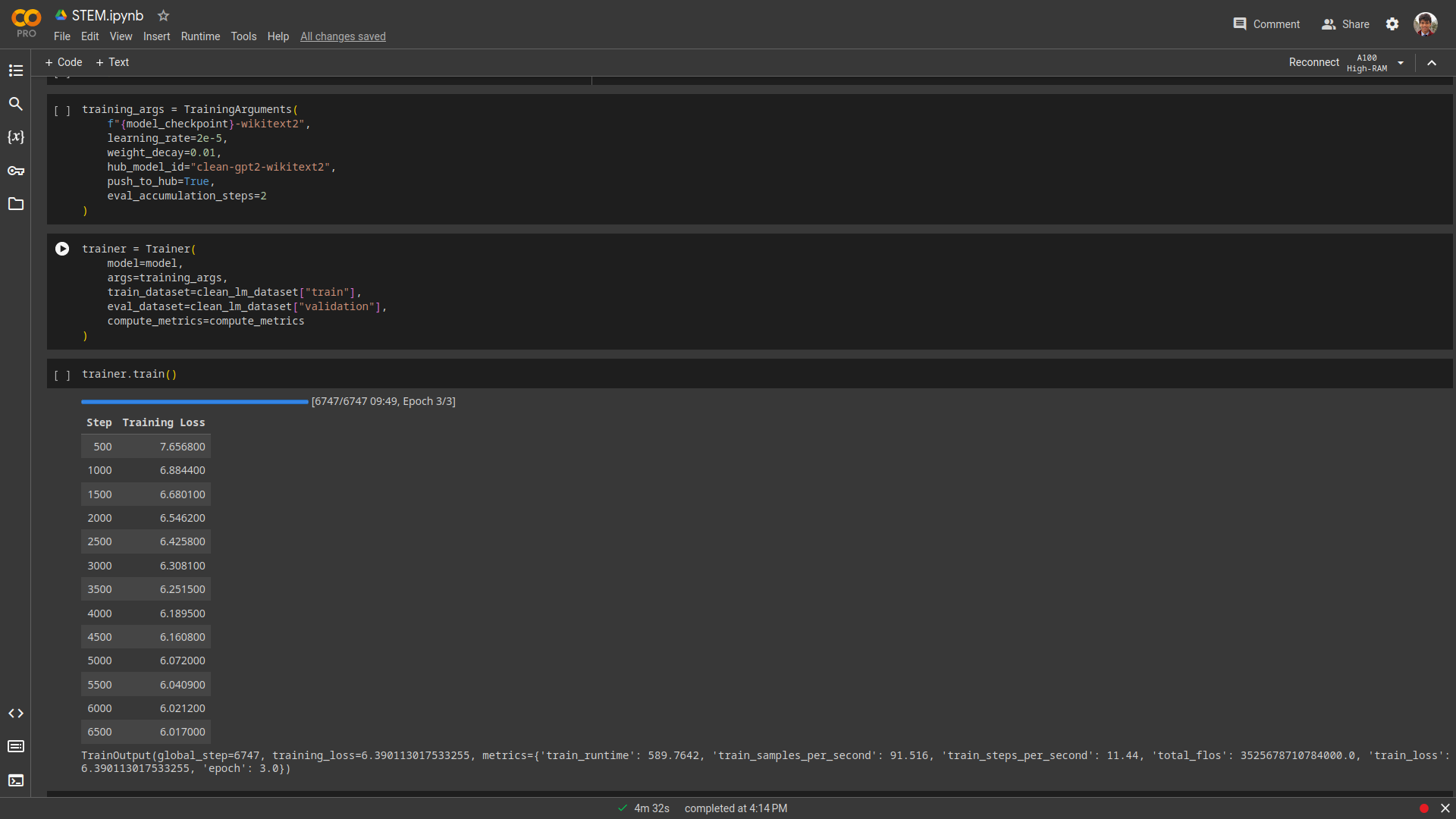
Model training in Google Colab
Armaan Priyadarshan
Advisor: Dr. Kevin Crowthers, Ph.D.
This project addresses the challenge of ensuring the quality of massive language model training datasets, which can be as large as terabytes or petabytes. As these datasets grow in size, manually checking for errors becomes impractical. We developed a data cleaning technique specifically for language model datasets, tested it on the WikiText dataset, and found that it significantly improved the model's performance, highlighting the importance of such techniques for maintaining data quality as datasets continue to scale up.
Preliminary dataset analysis conducted in VSCode
Model training in Google Colab