Background
Artificial Intelligence (AI) is used everywhere in daily life, the medical field, and various other
settings (Yip et al., 2023; Tinao & Jamisola, 2023). Automatic Speech Recognition (ASR) is a subfield
within Artificial Intelligence that is commonly used for transcription services, virtual assistants, and
translation devices. Technology is always evolving, and the way we interact with it is also changing.
Voice is the easiest and most effective way of communicating with technology. This led to the concept of
virtual assistants, an auditory way to interact with technology. We already rely on virtual assistants
to turn on and off the lights in a room, stream music, or as search engines (Subhash et al., 2020).
How Automatic Speech Recognition Works
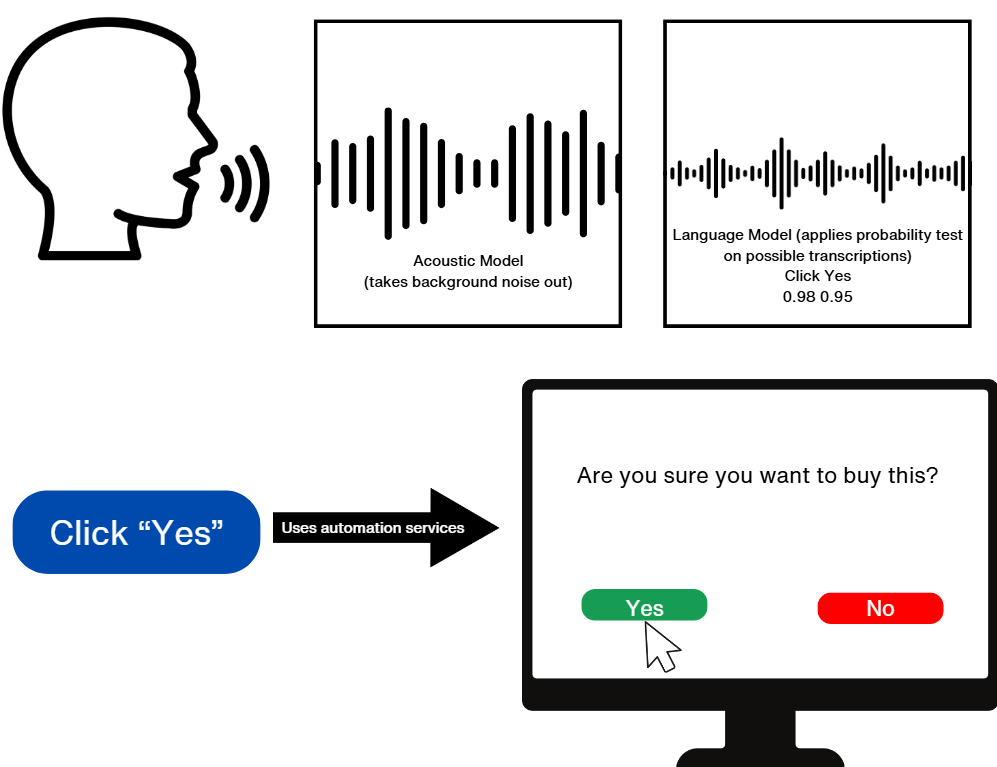
ASR is the driving principle behind speech recognition. It complements another component of speech
recognition, Natural Language Processing (NLP) which allows virtual assistants to comprehend both the
meaning of what a user has stated, but also to infer implicit nuances (Bajpai et al., 2024). Natural
Language Processing creates a better contextual understanding of user queries through semantic analysis.
Automatic Speech Recognition systems initially record speech and save the speech as a file, the file
will then be cleaned of any background noise and analyze what is stated sequentially. Probability tests
are applied to recognize all the words that complete the input. Finally, it will produce an output in
the form of text content (Subhash et al., 2020).
Past Use of Automatic Speech Recognition
Virtual Voice Assistants are a common application of Automatic Speech Recognition. Most people have used
Siri, Alexa, Cortana, or Google Assistant in order to search for information, send text messages, or
play music. A great application of voice assistants can be for those with restricted movements that make
it difficult to use technology. Verbal communication with a virtual assistant can accomplish tasks
without having to touch the device. Voice Assistants are a way to make our lives more convenient by
reducing the time it takes to complete tasks. Today, Voice Assistants are integrated into many devices
in our lives, such as cell phones and computers, and are available to the general public. Some
assistants are hardware-based and made to do one thing, like Alexa’s wall clock, and others are
software-based like the assistants someone would find in a phone (Singh et al., 2022).
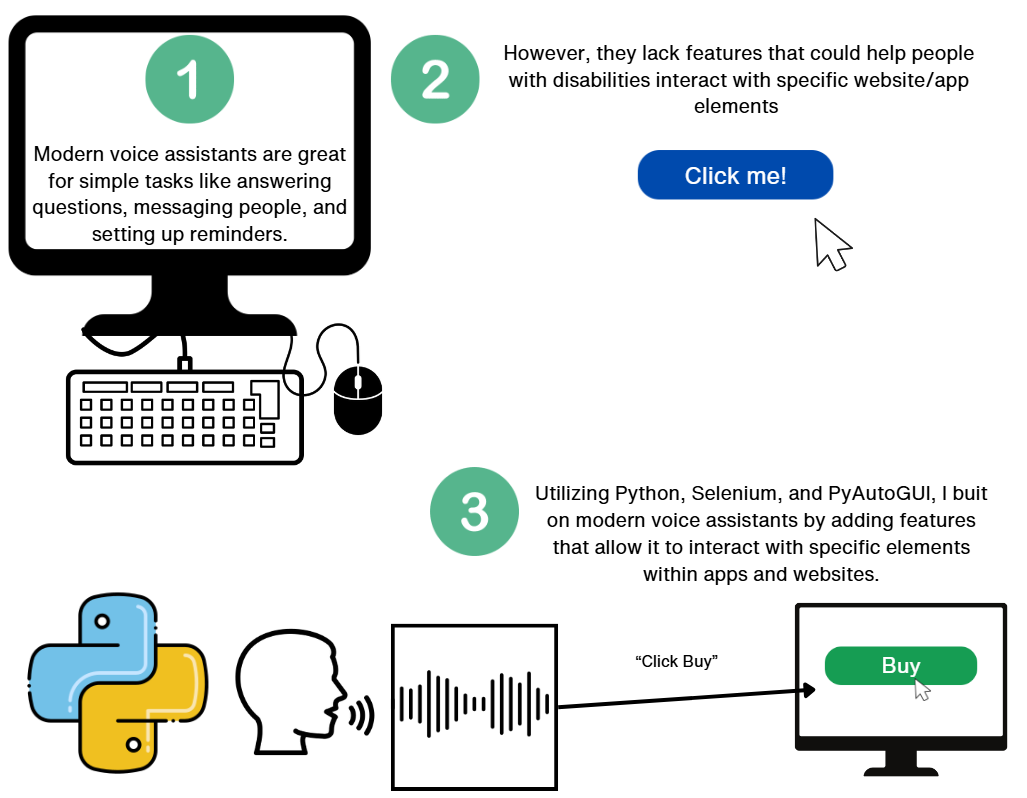
While they are great for retrieving information, there is still room for improvement when it comes to
user intractability. Common voice assistants like Siri, often contain simple app and web interaction
features that can retrieve information like searches. However, they lack giving users more
intractability with websites. This kind of feature can be significantly helpful to those who have
limited mobility.
Tools
The goal of this project was to fix weaknesses that are found in Voice Assistants. These weaknesses were
fixed using a programming language named Python, which contains large amounts of resources and libraries
that were utilized for this project. This software can be used by anyone; however, it is meant to aid
those with restricted mobility due to diseases and accidents. The program is split into two main
components, speech recognition and local interaction. The first component uses the speech recognition
Python library. This library allows someone to speak and then return the content in text form. It uses
the same concept of Automatic Speech Recognition and helps identify commands. The second component is
more complicated as there are many forms of local interaction. The program used the Python libraries
WebBrowser and PyAutoGui for tab control and key bind access. It also used Selenium Web Driver to
interact with web elements. At times, the program will speak to the user. This is done using the pyttsx3
library. The input can be a standard user microphone, and the output can be a standard speaker.
Future Steps
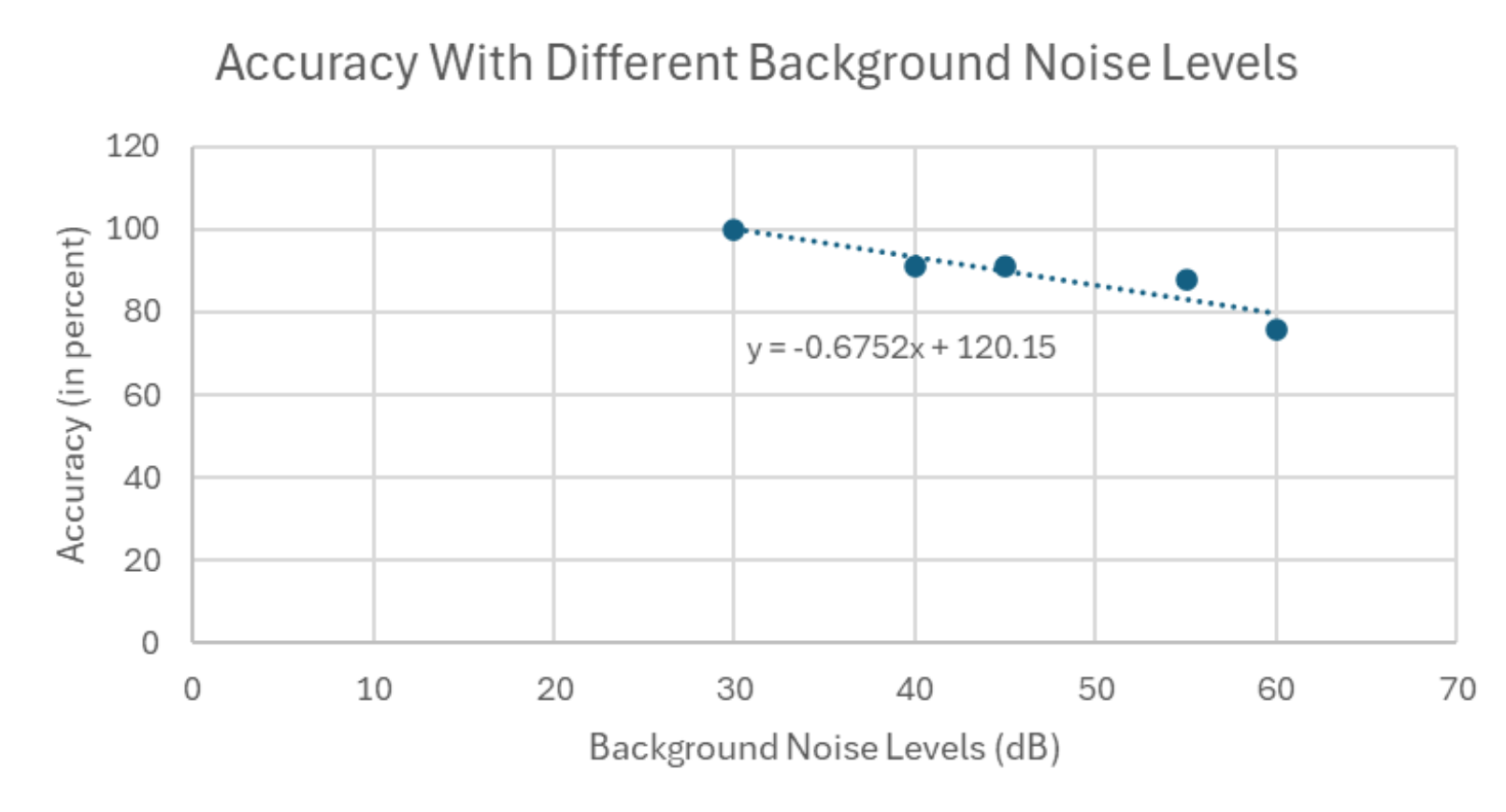
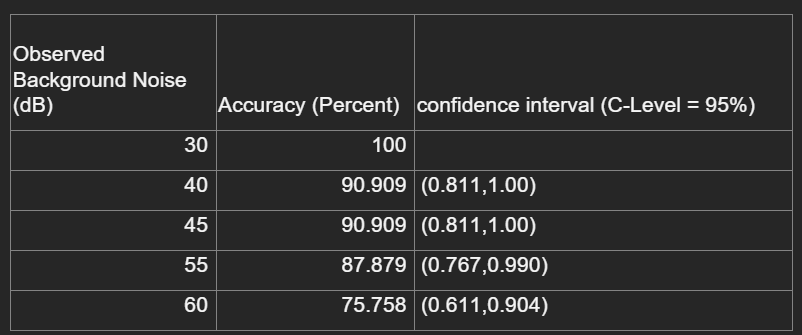
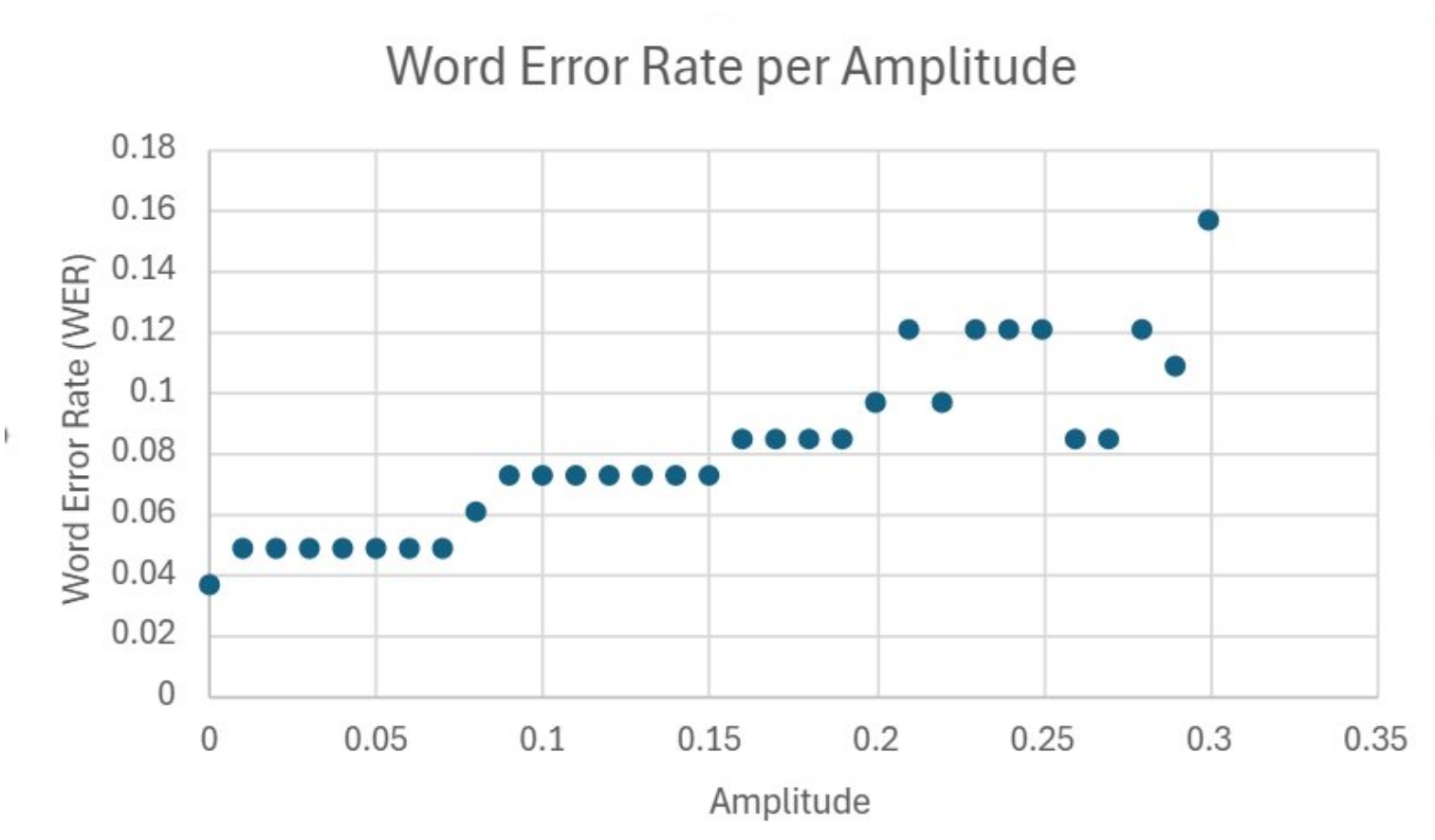
The Voice Assistant can be improved by creating a more accurate Automatic Speech Recognition model as
the current Google Speech-to-text model that is being used struggles with recognizing speech in noisy
environments. An approach that can be used to fix this is training the ASR model through Spectrum
Matched Training as it shows higher accuracies in noisy environments (Prodeus & Kukharicheva, 2016).
Another step can be greater application intractability for local applications. Cross-platform file
searches can also be implemented as the current program has only been tested through a Windows operating
system. Another feature that can be implemented into the program is an intention detection system that
will trigger the assistant when it feels that it is needed by detecting if the user is requesting the
assistant based on the volume of the request relative to other sentences in the conversation surrounding
it (Barton, 2015).