In STEM 1 with Dr. Kevin Crowthers,
throughout the course of 6 months, we create our independent research
project to solve a problem in our world. In this class, we learn how
to write various technical documents, conduct research, and present
our work. This class especially strengthened my public speaking skills
and helped me overcome my fear of presenting.
Utilizing Machine Learning to Create an Effective Tool for
Managing Food Waste
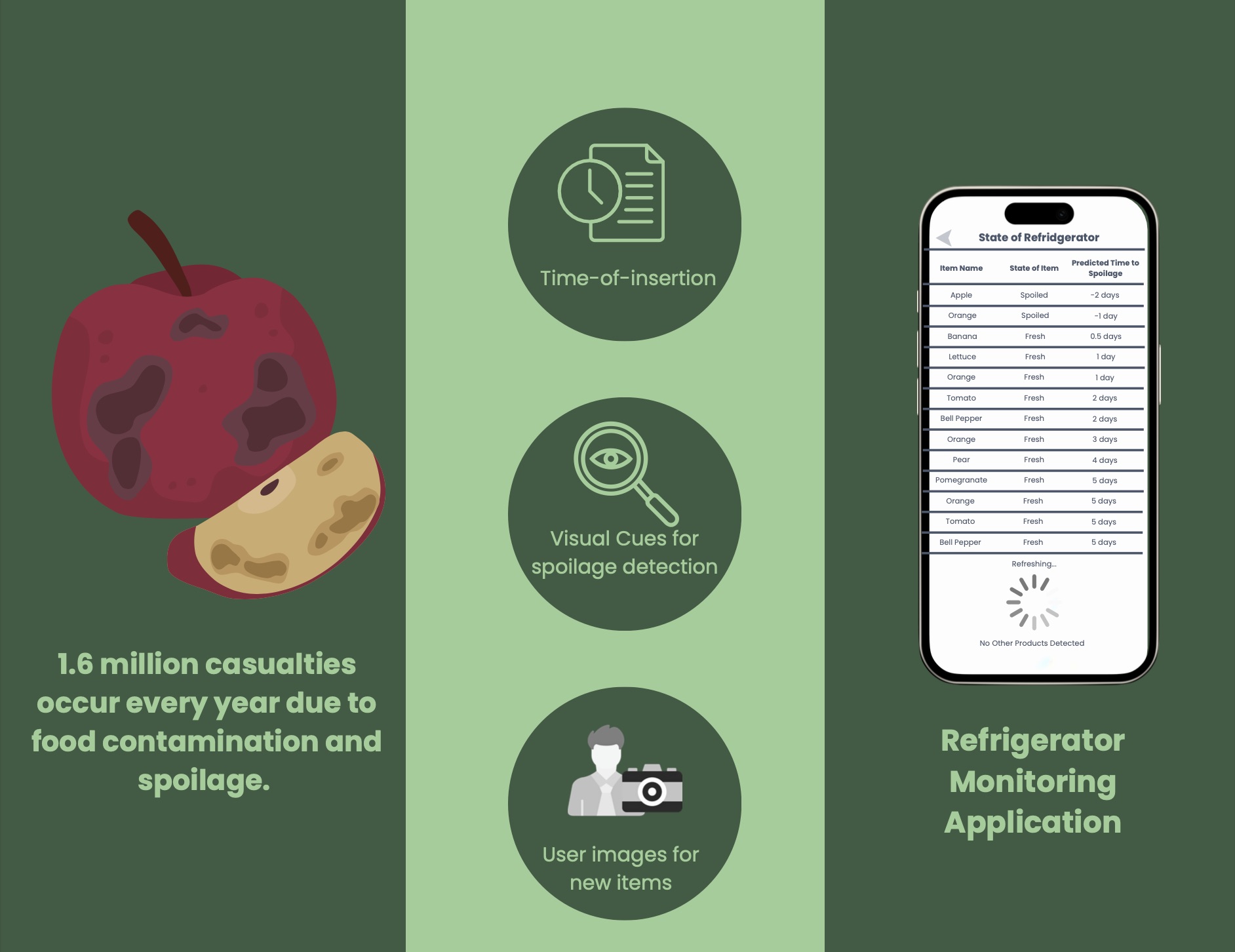
A refrigerator system, which detects the state of food
using visual cues, time data, and user-provided images, is a
practical solution to food waste. When tested on both known and
unknown products, the deep-learning focused system was able to
accurately identify spoilage.
QUAD Chart
This QUAD chart summarizes my science fair
project. The first section outlines the problem of food spoilage and
includes a graphical abstract. The second section presents a concise
visual methodology that highlights the key steps of the project. The
third section provides a basic analysis of the data, supported by two
figures that illustrate the findings. The final section presents the
project’s conclusions and outlines potential next steps for further
improvement.
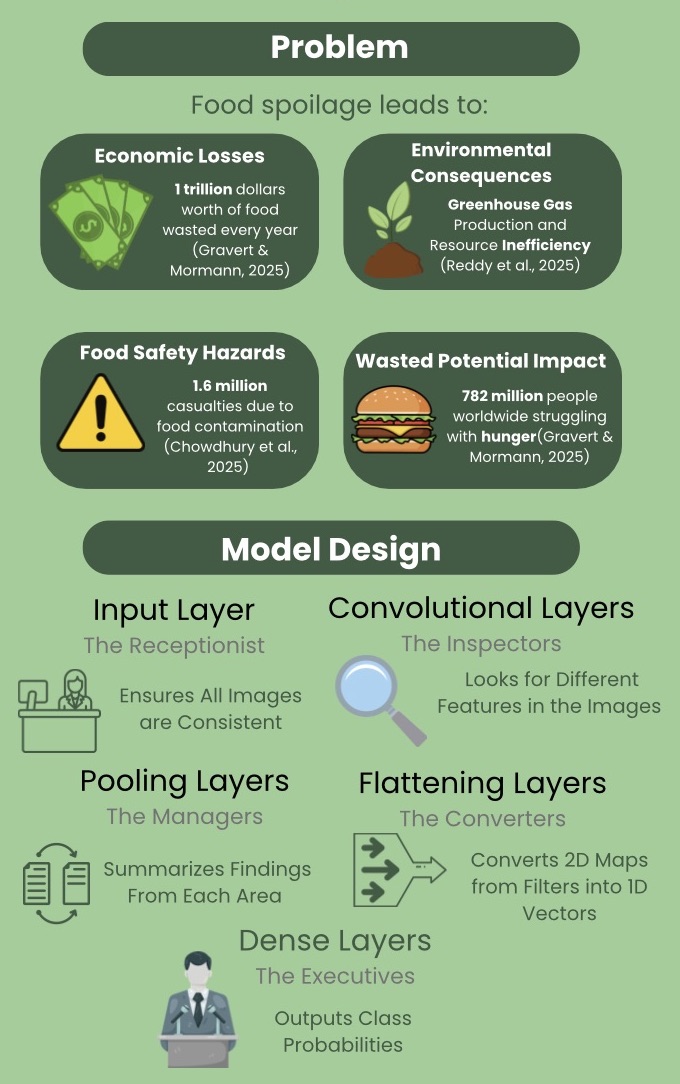
Food waste is a significant issue for human
health, environmental preservation, and the global economy, with
household spoilage being a major contributor. Currently, spoilage
detector methods are inaccurate, manual, or limited in scope. This
project constructs a spoilage detection system for refrigerators using
deep learning models reliant on visual cues and the time elapsed
inside to detect spoilage in both familiar and unfamiliar items. Then,
data about the state of products is provided to the user through an
application made to alert. To train the models, the system relies on
augmented data of an object from an external dataset or user-provided
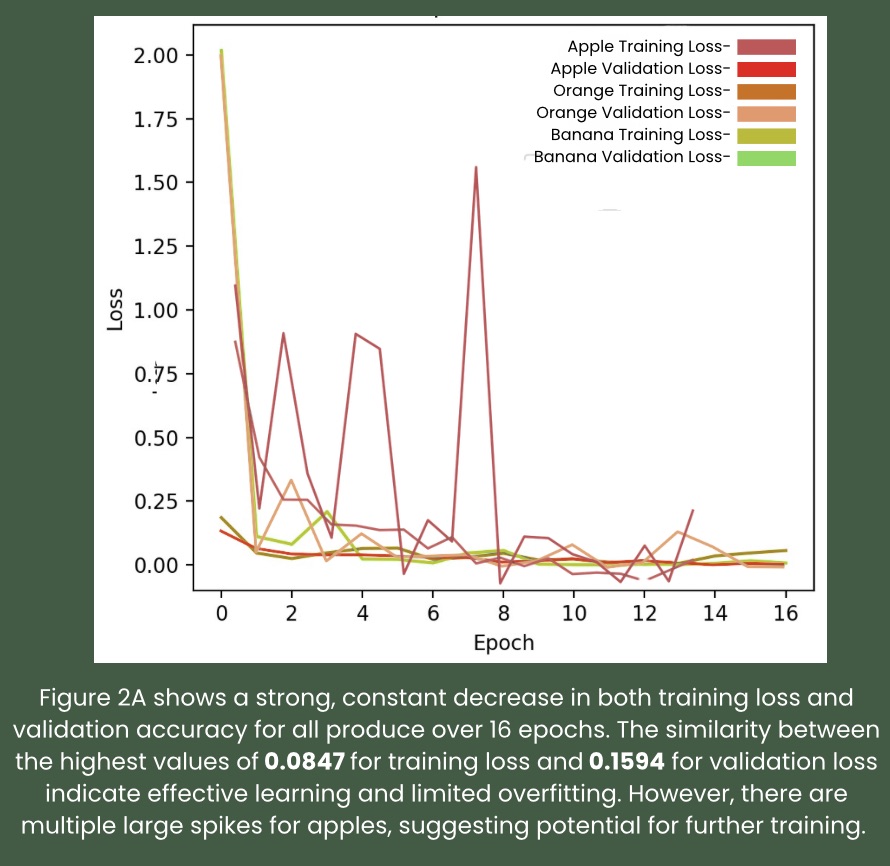
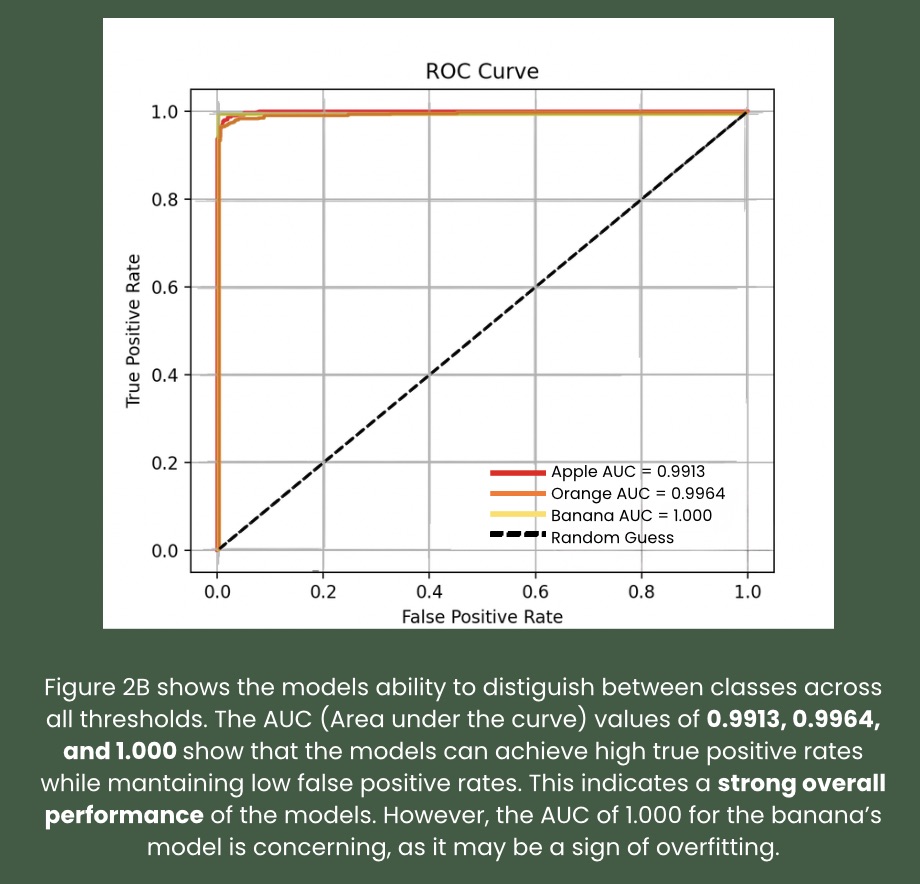
images. To detect spoilage, a convolutional neural network was used,
achieving an accuracy of above 98.13 percent for 3 different types of
fresh produce. For unfamiliar products, a convolutional neural network
was trained through augmented user-given images. A YOLOv8 model was
used to extract bounding boxes from inside images, correctly
identifying the name and state of the product 61.24 percent of the
time. The experimental results suggest that the system accurately
detects spoilage in items, outperforming traditional manual systems.
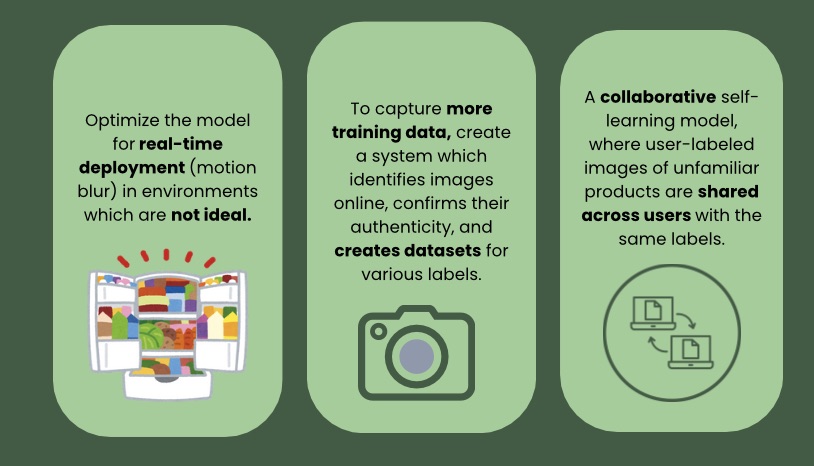
However, the system does struggle to identify the object under
inconstant conditions. This approach addresses the challenges of
autonomous food monitoring and provides reliable alerts to reduce food
spoilage.
Urban households need a system which detects whether fresh and
cooked foods in refrigerators are demonstrating signs of spoilage
to reduce the amount of food waste.
Objective
Identify food spoilage in common and unfamiliar items in household
refrigerators using visual cues, insertion and removal times,
and user-provided images, and to display the state of foods to reduce
waste.
Background
Food waste is a significant issue affecting the global economy, human
health, and environmental elements (Chigurupati et al., 2025). Every
year, over one trillion dollars worth of food is wasted instead of
being used to address the hunger of 782 million people worldwide
(Gravert & Mormann, 2025). Furthermore, the consumption of spoiled
foods has impacted the spread of foodborne illnesses, with 1.6 million
fatalities attributed to food contamination per year (Chowdhury et
al., 2025). Additionally, food waste affects the environment due to
the release of methane and other greenhouse gases during the
production process, causing resource inefficiency (Reddy et al.,
2025). Currently, a prevalent issue is the wastage of food before and
after the sales process, which contributes 60% of the total food waste
(Gravert & Mormann, 2025). This problem is especially
prevalent in urban households with busy storage locations, such as
packed refrigerators. With the amount of food available, storage in
such areas becomes disorganized, leading to items being forgotten and
eventually spoiling. Often, to prevent such issues, households
manually record the items inside their refrigerators and the time they
were stored. However, this method is extremely time-consuming and
often results in individuals forgetting to record items. A common
cause includes human dependency for detecting food waste, which leads
to large expenses while being unreliable (Chigurupati et al., 2025).
Current automatic methods are either unable to identify a variety of
foods, struggle to detect spoilage, or require manual input from a
user for each item. Thus, there is a need for urban households to have
a camera system that detects whether fresh and cooked foods in
refrigerators show signs of spoilage to reduce food waste. This
project addresses various problems, including the lack of surveillance
of food in refrigerators and their eventual spoilage due to the lack
of reminders for usage. It also includes solutions to inaccurate
prediction systems and the lack of flexibility in product type.
To identify visual spoilage, various types of deep learning models
were used. Deep learning is a branch of artificial intelligence that
enables computers to identify complex patterns from large amounts of
data. The models automatically identify and classify objects in images
without manual rules, allowing them to handle complex visual tasks
such as food spoilage detection (LeCun et al., 2015). Convolutional
neural networks (CNNs) are a common type of deep learning model used
for image analysis, while object detection models such as YOLOv8 by
Ultralytics can isolate multiple items within an image. By using such
technologies, spoilage is identified automatically, which is difficult
to achieve with traditional manual methods (Chigurupati et al., 2025).
However, for these models to be effective in all situations, accurate,
abundant, and structured data is essential. Data preparation
consists of many steps, including locating and recording the data,
formatting it properly, and dividing it into categories. First, the
model must have access to accurate data. Then, the data is formatted
to be consistent and applicable to the specific model. After storage,
the data is divided into testing, validation, and training sets with a
ratio of 7:2:1 (Wang et al., 2021). This ratio allows sufficient
training data while enabling predictions for validation and testing.
Often, there may not be enough data available, leading to the need for
data augmentation. Data augmentation involves slightly altering an
image and adding it to the dataset for training and testing. Some
alterations include rotations, slight color changes, reflections,
translations, and adding speckles. Convolutional neural
networks (CNNs) are designed to automatically analyze and classify
images through visual data. These models extract features from images
to identify subtle differences that may indicate spoilage, such as
changes in color or shape (Chowdhury et al., 2025; Chigurupati et al.,
2025). CNNs are useful in food monitoring due to their ability to
generalize across various food types without requiring specific manual
rules. By learning directly from image data, these models provide a
scalable solution for large datasets. After the data is
prepared, the CNN model is constructed and used for training. The CNN
model consists of five main types of layers: the input layer,
convolutional layers, pooling layers, a flattening layer, and dense
layers. The input layer ensures the images are formatted correctly and
consistently. The convolutional layers identify patterns, with each
subsequent layer identifying more complex patterns. For example,
initial layers detect edges and colors, while later layers analyze
signs of spoilage such as spots or wrinkles. After each convolutional
layer, a pooling layer summarizes the most important features within a
specific grid area. The flattening layer converts two-dimensional
feature maps into one-dimensional vectors, allowing dense layers to
make final classification decisions. A dropout layer is used to
prevent overfitting and improve generalization (Chowdhury et al.,
2025). This layer ignores a percentage of learned patterns to ensure
the model focuses on recurring features. Important hyperparameters
include the learning rate, the number of epochs, and the dropout rate
(Chigurupati et al., 2025). These methods enable the system to detect
spoilage patterns and improve food storage efficiency.
Although CNNs are effective for classifying individual images,
real-world refrigerators often contain overlapping items that require
object detection. To address this challenge, an object detection model
called YOLOv8 was used. This model provides bounding boxes, which are
rectangular frames around identifiable items, along with confidence
scores (Wang et al., 2021; Hemavathy et al., 2023). YOLOv8, standing
for "You Only Look Once", is suitable for fast, real-time detection
(Wang et al., 2021). Due to its ability to generate accurate bounding
boxes, YOLOv8 identifies foods in images and saves a frame of each
item for further analysis. Despite advances in deep learning
and object detection, current spoilage detection systems still have
limitations. Many struggle with cluttered and realistic environments.
As a result, most retail applications require manual input for each
item or are limited to specific food types (Chigurupati et al., 2025).
Additionally, user interfaces are often unclear and rarely provide
real-time actionable alerts. These gaps justify the development of a
deep learning based system that detects early signs of spoilage across
multiple food items and provides reliable alerts to reduce household
food waste.
Procedure
Use an apple as the fruit for the preliminary model
Use the Fruits Fresh and Rotten Kaggle Dataset to organize
the information into accurate folders for training and
identification.
Create a CNN model to train with the data from the
dataset, focusing on preventing overfitting.
For more advanced models, it may be wise to use more
complex CNN network structures, like VGG, ZFNet, GoogLeNet (Liu et
al., 2016).
Identify whether certain examples of the product have
spoiled with an accuracy of greater than 90% within a training
period of 10 days
Identify spot spoilage and color changes to predict
spoilage.
Use the barcode or the use-by-date if applicable to
predict spoilage.
Use the insertion and removal time of the product to
predict spoilage.
Combine the three situations to identify the most probable
class.
Identify spoilage in at least 5 more items with an accuracy
greater than 90% for each within a training period of 10 days
Use the Fruits Fresh and Rotten Kaggle dataset with access
to bananas and oranges as well.
Allow the model to contain multiple classes and classify
each product.
Allow the user to input full images of new products, provide
a label for the product, and get a prediction from the model after
10 inputs with an accuracy of 70%
Collect the data and augment it to prevent overfitting.
Create an autonomous system where the model can begin to
train itself and adjust hyperparameters until it can predict the
new product.
Allow the model to make predictions from the information
provided and store the learning data.
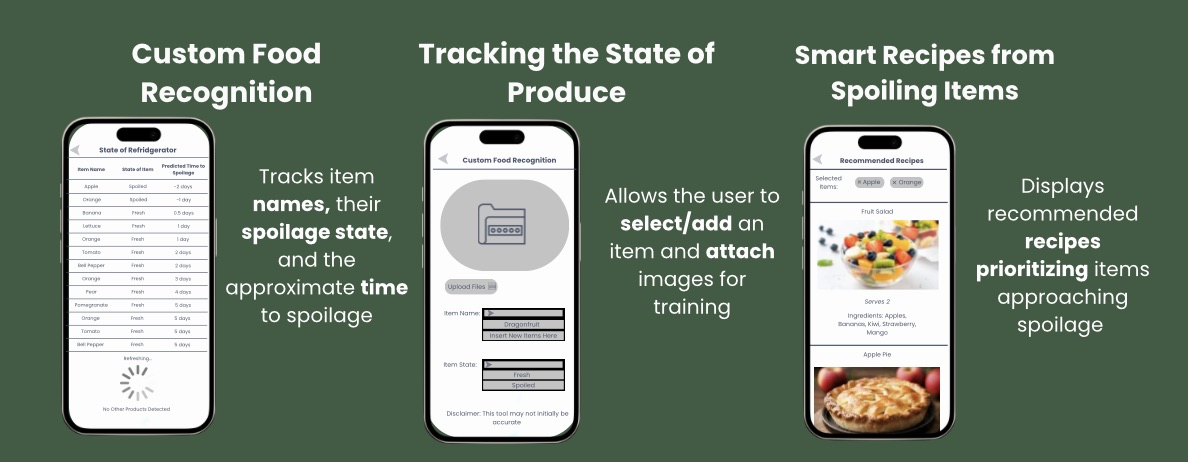
Display the model through an easy-to-understand application
which streamlines the process of checking for food spoilage
Create an interface which displays the items present in
the refrigerator and their approximate spoil-by date.
Alert the user when the spoilage date is approaching.
Provide a user-friendly system to capture images for
future predictions with new products.
Assist in recipe choice through existing recipe AI models
and use a probe object to identify the amount of food as it is
used for volume calculation of food items (Wasif et al., n.d.).