
STEM is taught by Dr. Crowthers (who is known by many as the STEM Overlord). From the start of the year until our school science fair in February, we work on our independent STEM research projects. This is an opportunity for us to conduct research and experimentation on a topic of our choosing, and present our findings. We also become acquainted with scientific and technical writing through assignments we complete based on our projects.
Below is an overview to my project for this year, for which I aim to employ a multimodal approach to improve upon existing driver safety systems and effectively detect drowsy drivers in an automotive vehicle.
An overview of preliminary data collected
Driver fatigue is a leading cause of vehicular accidents today. Although there are safety systems being increasingly implemented in modern automotive vehicles, most detect drowsiness after the hazardous driving has already occurred based on singular, individual indicators from the movement of the vehicle. Such systems primarily rely on vehicle-based data rather than the physical state of the driver. My project aims to provide early intervention by developing a multimodal system that monitors the driver in real-time. This design incorporates sensor fusion from three modules that are connected to a RaspberryPi: a computer vision system to track eye closure, an FSR array to detect postural slumping, and an accelerometer to identify irregular head movements characteristic of microsleeps. Furthermore, by utilizing convolutional neural network (CNN) based machine learning for the vision module, a much more accurate and reliable assessment of a driver's state (over traditional methods) can be provided. The sensor fusion system also compensates for the weaknesses of individual sensors, minimizing spurious detections. After conducting testing, I have sufficient evidence to say this design is indeed a robust, low-cost safety system that can detect the earliest signs of fatigue and alert a driver within two seconds, potentially preventing life-threatening accidents before they even occur.
Driver fatigue is a leading cause of road accidents today; however, most existing safety systems detect drowsiness reactively based on vehicle motion after hazardous driving has already occurred. By relying on singular indicators, these systems often detect fatigue closer to the moment of a potential accident, increasing the risk of life-threatening collisions. This project aims to mitigate this risk by adopting a strategy for early intervention through a multimodal system that monitors the driver’s physical state in real-time. This design incorporates sensor fusion from three modules integrated via a Raspberry Pi: a camera-based computer vision system utilizing convolutional neural network (CNN) machine learning to track eye closure, a seat-based force-sensing resistor (FSR) array to detect postural slumping, and an accelerometer to identify irregular head movements characteristic of microsleeps. By combining visual, positional, and kinematic data, the system compensates for the weaknesses of individual sensors—such as cameras failing in poor lighting or seat sensors misinterpreting a simple shift—minimizing spurious detections. Experimental testing provided sufficient evidence that this design is a robust, low-cost safety system, achieving 98% accuracy in classifying drowsy states and alerting the driver within 1.5 seconds. These results demonstrate the reliability and accuracy of this system, offering a significant improvement over existing vehicle-based methods, potentially preventing accidents before they even occur.

Driver fatigue is a major cause of vehicular accidents despite existing detection methods. Single-mode detection techniques alone are often insufficient to monitor complex driver states, while vehicle-based systems detect drowsiness only after hazardous driving has already occurred.
This proposal's objective is to construct and validate a multimodal driver fatigue intervention system. The work proposed will combine data, from three sources—a camera vision system to detect eye closure, an array of force-sensing resistors (FSRs) for identifying a slumped posture, and an accelerometer to detect sudden head tilt/movement. The detection of such behavior would result in the driver being determined to be drowsy, subsequently triggering the alert system in an effort to reawaken the driver.
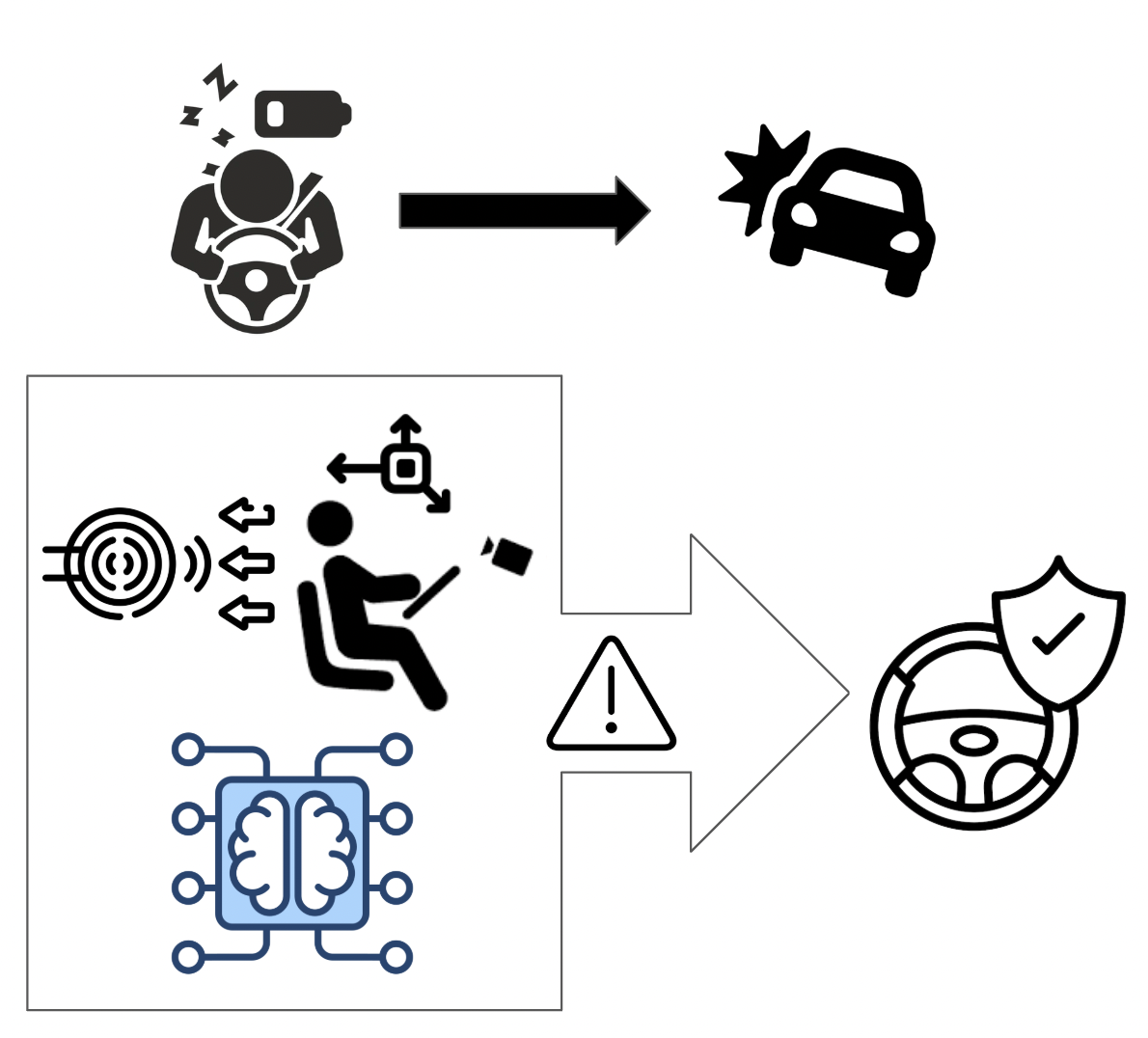
Driver fatigue is a major cause of vehicular accidents despite existing single-module detection methods; they often lack the accuracy and robustness required for reliable real-time safety systems. The goal of this project is to develop and construct a Multimodal Driver Fatigue Intervention system that integrates various sensor inputs and machine learning to provide accurate, real-time detection and mitigation of early-stage driver drowsiness. This project aims to develop a solution to the issue that simple image processing techniques alone are often insufficient to address the complexity of driver state monitoring (Jose et al., 2021), a limitation that is frequently highlighted in surveys of driver behaviour analysis (Wang et al., 2022).
Detection Methods
Early detection systems of driver fatigue primarily rely on behavioral indicators. One such indicator is eyelid closure, effective for initial screening (Sathasivam et al., 2020). This screening is done using facial feature markings and object detection, classified into a drowsy or awake state (Dasgupta et al., 2013). However, achieving high accuracy in detecting drowsiness on the driver’s face visually in real-world driving environments requires moving beyond basic image processing to incorporation of more advanced methods, such as multi-Convolutional Neural Network (CNN) Deep Models, which utilize facial subsampling for enhanced robustness (Ahmed et al., 2022). The research in this area essentially established that the driver could be monitored using vision-based systems, although with limitations. A multimodal approach is essential to overcome the limitations of purely visual systems. Vision-based monitoring often faces challenges with changes in lighting or other obscurities (Wang et al., 2022). This project integrates inputs from an accelerometer for head movement analysis and a posture sensor array for seat data (applied pressure measurements). Data fusion in general is critical for reliability of the design, for one sensor to compensate for the weaknesses and shortcomings of another, minimising the output of spurious data. (Wang et. Zhao, 2022).
Machine Learning
The combination of data from these sensors requires complex algorithms. Machine learning algorithms are a viable approach, processing continuous input from the camera, accelerometer, and posture pressure FSR to identify patterns between physical indicators. Additionally, the deployment of models utilising CNNs ensure that the system can learn the unique patterns of drowsiness based off of the training dataset (Ahmed et al., 2022). This integrated machine learning approach which incorporates neural networks (Ed-Doughmi et al., 2020) leads to an effective comprehension of the state of the driver, and the driver can subsequently be alerted to avert a potential collision if necessary.
Equipment and Materials
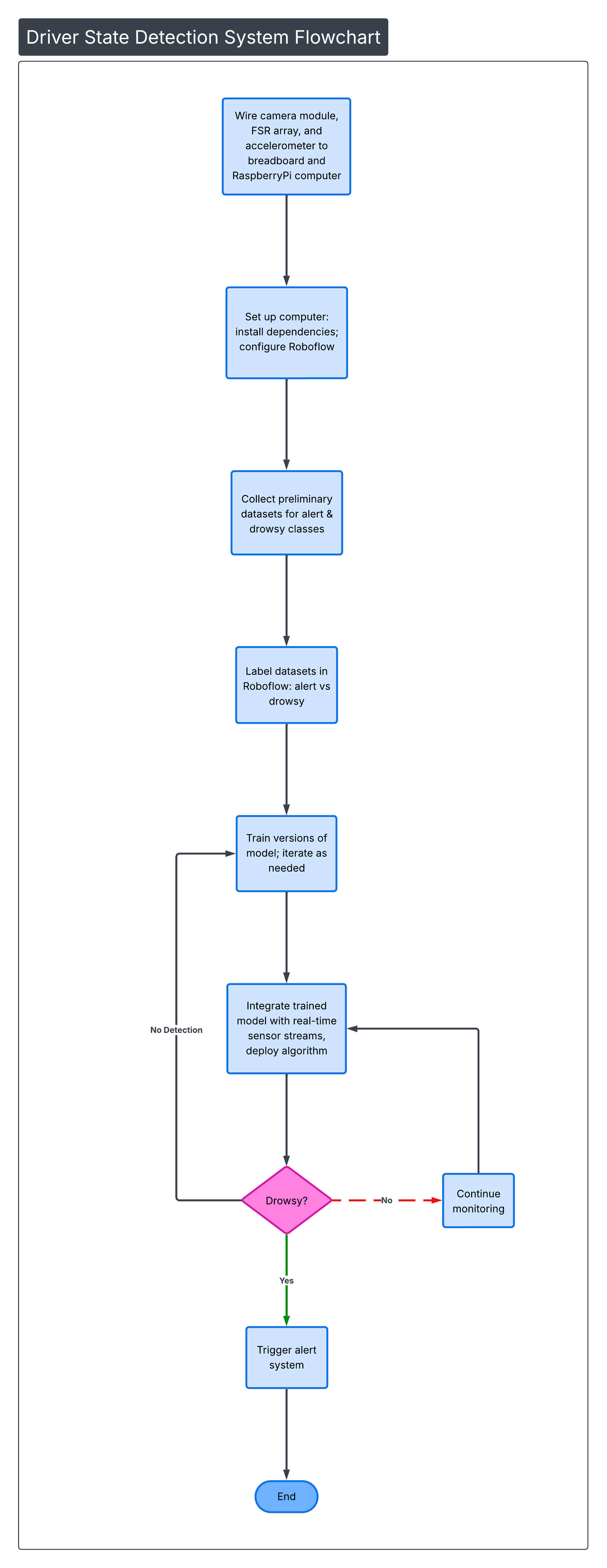
The construction of the Multimodal Driver Fatigue Intervention system required a high-definition vision module for real-time facial monitoring and an array of force-sensitive resistor (FSR) posture sensors to collect seat pressure data. To account for the irregular head movements characteristic of microsleeps, an accelerometer was integrated into the sensor suite. The computing environment was established on a high-performance computer utilizing Roboflow for the management of a diverse, annotated dataset exceeding 6,000 images, which served as the foundation for training the multi-Convolutional Neural Network (CNN) architecture. Additional materials included the hardware interfaces necessary to bridge the sensor array with the processing unit and the physical components of the alert system.
System Setup and Calibration
The initial phase involved setting up the computer with all necessary software dependencies required for image processing and sensor data fusion. Once the environment was prepared, the vision module, accelerometer, and FSR array were connected to the computer and calibrated individually to ensure synchronized data streams across all hardware. During this phase, the system was configured to identify specific object detection parameters for the vision module and pressure distribution patterns for the seat module. Preliminary datasets were then collected from all sensors for both alert and drowsy states. These datasets were labeled and stored to provide the data necessary for the subsequent training and validation of the machine learning model.
Machine Learning and Integration
The machine learning component focused on training a CNN-based object detection model using the diverse dataset of over 6,000 annotated images via the Roboflow platform. By utilizing this extensive training set, the CNN approach ensured a high level of robustness in detecting drowsiness compared to basic image processing (Ahmed et al., 2022). Once training was complete, the machine learning model’s output was integrated with the accelerometer and FSR data streams to algorithmically determine if the driver was drowsy or awake.
Multi-Sensor Performance Metrics
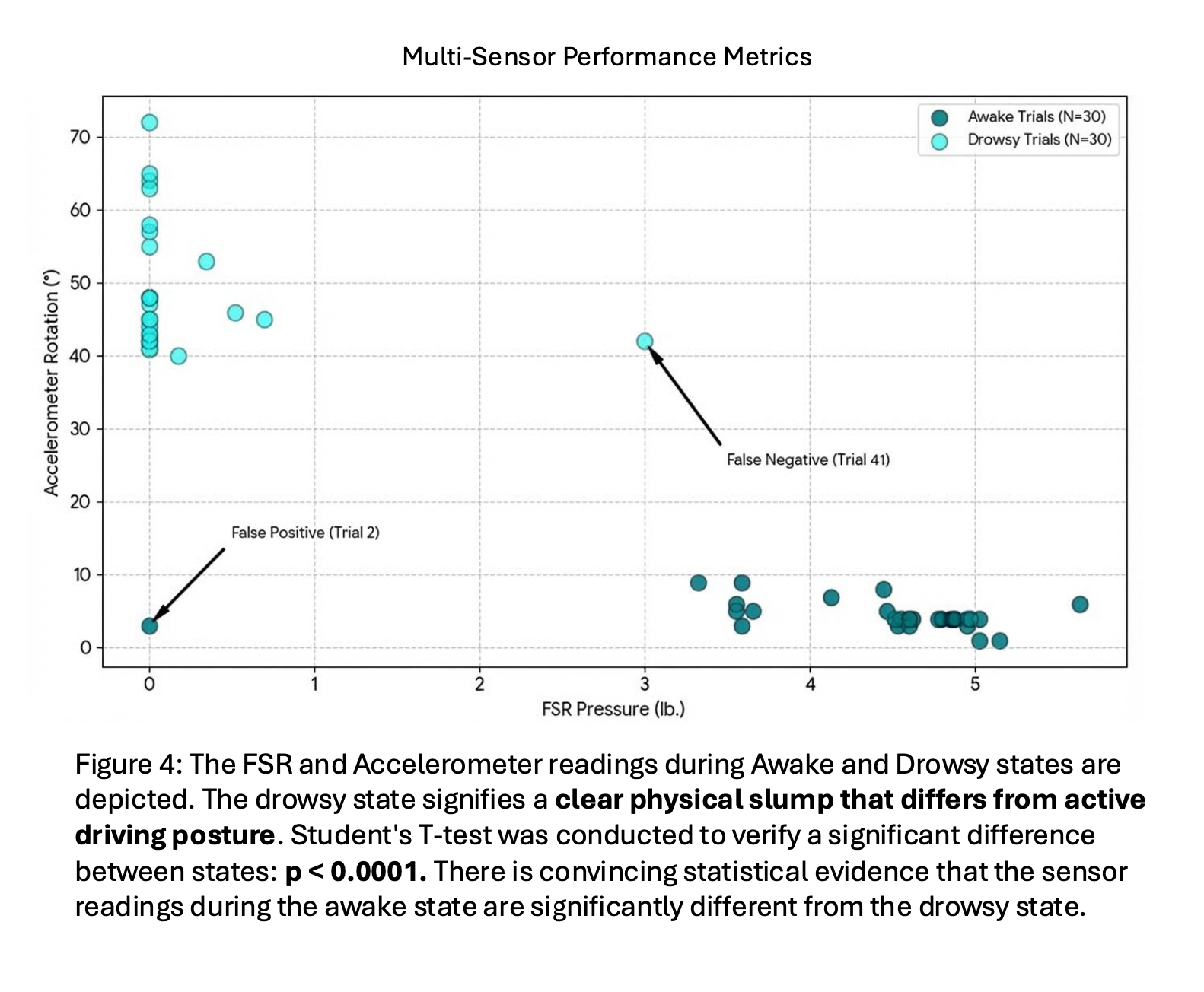
Figure 4 depicts the FSR and Accelerometer readings during the "Awake" and "Drowsy" states. The x-axis represents FSR pressure in pounds, while the y-axis is for Accelerometer tilt (degrees). A Student’s T-test was conducted to verify the statistical significance between these states (p < 0.0001). The results provide convincing statistical evidence that the sensor readings during the awake state are significantly different from the drowsy state. The drowsy state signifies a clear physical slump, characterised by the loss of pressure and increased head tilt.
Integrated Detection Accuracy
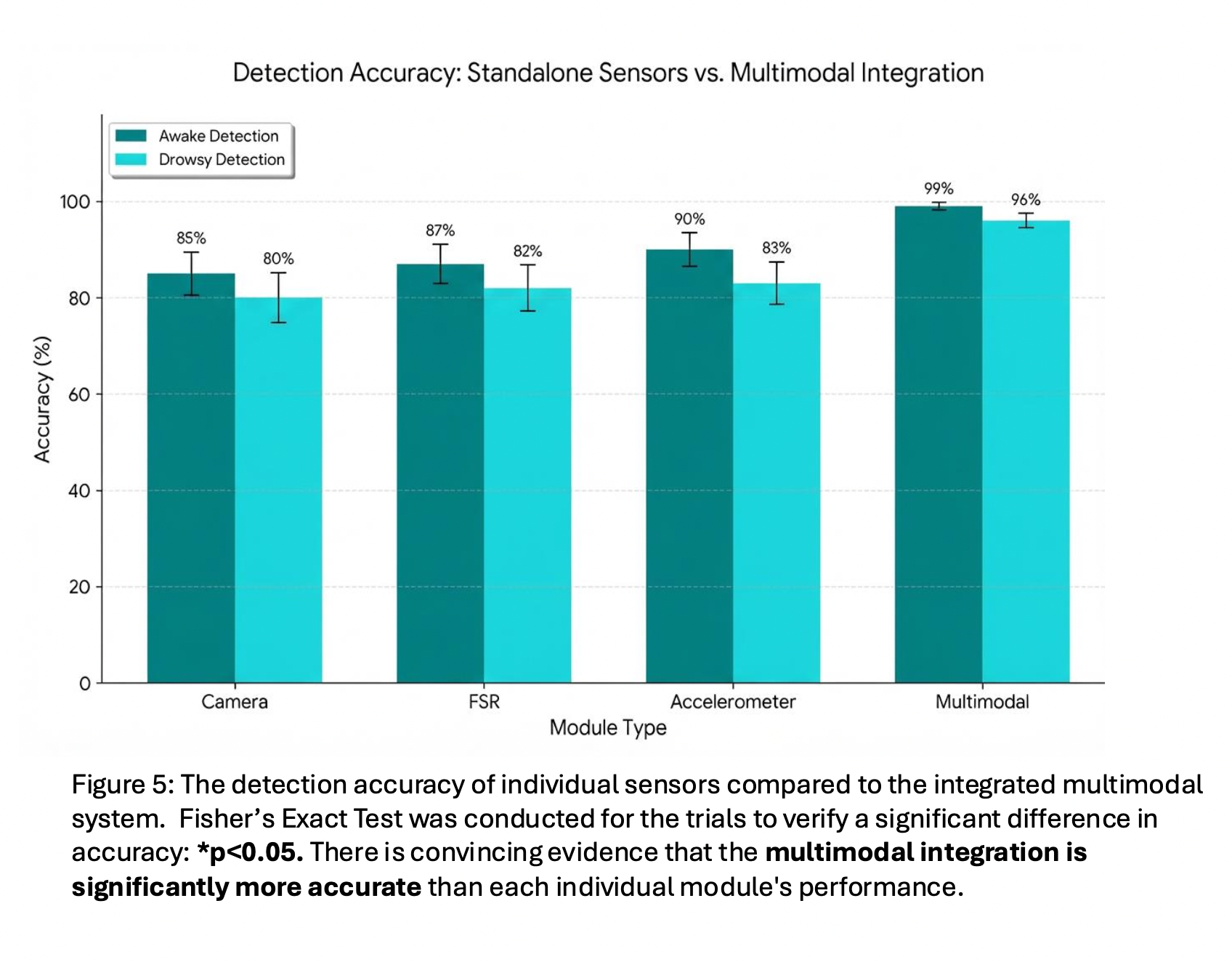
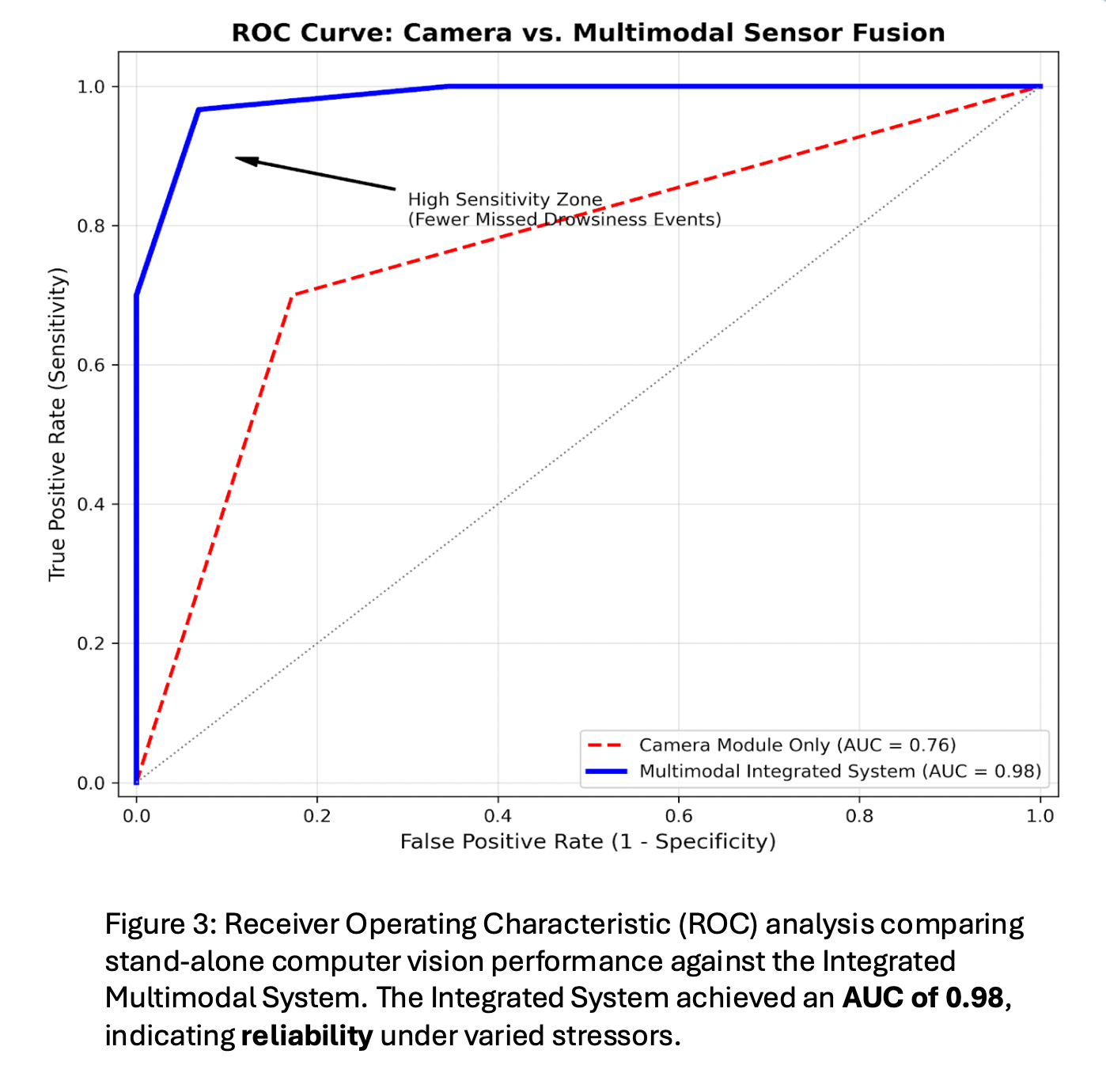
Figure 5 shows the detection accuracy of individual sensor modules compared to the integrated multimodal system. This was determined through trials of the Camera, FSR, and Accelerometer modules both independently and in fusion. Fisher’s Exact Test was conducted for these trials to verify a significant difference in accuracy (p < 0.05). This confirmed that the multimodal integration is significantly more accurate than each individual module’s performance.
Environmental Resilience: Illuminance
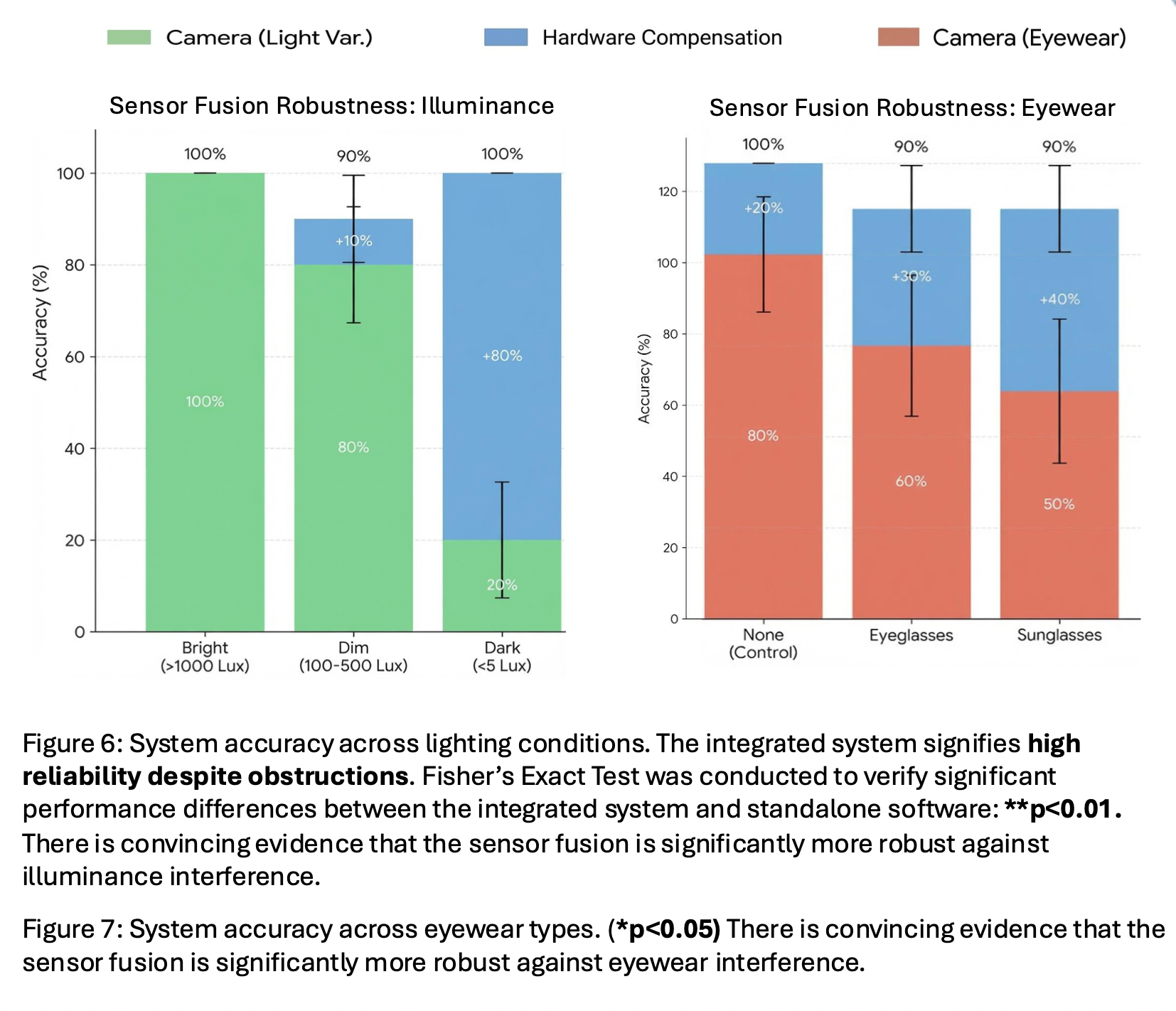
Figure 6 depicts the system accuracy across varying lighting conditions. Fisher’s Exact Test was conducted to verify performance differences between the integrated system and camera vision alone under these conditions (p < 0.01). The results show that the integrated sensor fusion is significantly more robust against illuminance interference than vision-only methods. The hardware components (FSR and Accelerometer) compensate for visual obstructions for the camera, allowing the integrated system to maintain high reliability despite the poor lighting.
Environmental Resilience: Eyewear
Figure 7 shows the results of system accuracy across different eyewear types: sunglasses and spectacles. The results are compared using Fisher’s Exact Test (p < 0.05). This was used to show that the various experimental groups affected the vision model's reliability. There is convincing evidence that the sensor fusion is significantly more robust against eyewear interference than a standalone camera module.
System Latency Analysis
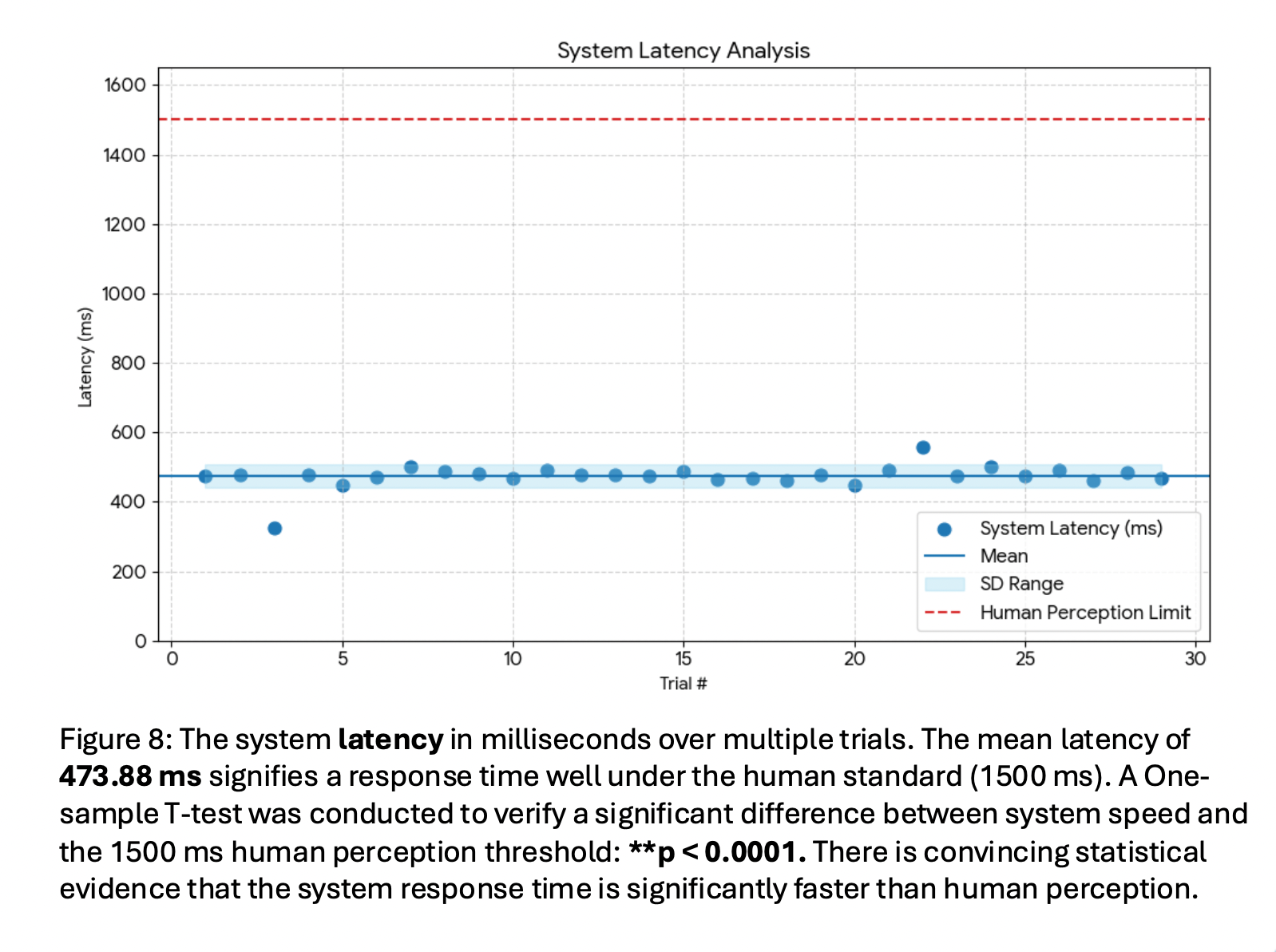
Figure 8 shows the system latency in milliseconds recorded over multiple trials. A one-sample T-test was conducted to verify a significant difference between the system speed and the 1500 ms human perception threshold (p < 0.0001). The mean latency of 473.88 ms signifies a response time well under the human standard of approximately 1.5 seconds. This conveys that the system response time is significantly faster than human perception, allowing for adequate time for intervention before a hazardous event occurs.
Discussion
In experimentation, the independent performance of the YOLOv8 camera module, FSR array, and accelerometer were evaluated against the integrated multimodal system to determine the feasibility of the proposed sensor fusion approach for real-time safety. While individual modules are capable of identifying specific markers of fatigue, results indicate that they remain highly susceptible to environmental variables when operating.
This is particularly evident when addressing the system's robustness against common driving stressors. Standalone computer vision models are often hindered by fluctuations in lighting or the presence of driver accessories. However, the integrated system maintained a high level of accuracy across various illuminance levels and successfully navigated the use of different eyewear types, such as sunglasses and spectacles. This implies that when visual data is compromised, the hardware-based physical sensor data from the FSRs and accelerometer provides a critical redundancy. This multi-layered architecture ensures that the system remains functional regardless of external conditions that would typically cause a software-only monitor to fail.
During a "nodding off" event, the FSR sensors detected almost a total loss of seatback pressure while the accelerometer identified a significant shift in head angle. Statistical analysis provided convincing evidence that the readings recorded during an alert state are distinct from those recorded during a drowsy state. This confirms that the drowsy state can essentially be characterised by a measurable physical slump that is distinct from an active driving posture, allowing the system to categorize these shifts as reliable indicators of fatigue rather than random movement.
Furthermore, system efficiency was analysed to ensure that safety interventions occur within a viable timeframe. While the standard human perception threshold for a hazard is approximately 1500 ms, this system achieved a mean latency of 473.88 ms. By maintaining a response time well under the human standard, the device is capable of delivering an immediate audio alert to reawaken the driver. This rapid response time is a crucial factor in bridging the gap between driver drowsiness and the prevention of a potential collision.
Conclusion
In conclusion, this project successfully achieved its objective through the development of a multimodal system that utilises YOLOv8 machine learning object detection alongside hardware sensor inputs to create a more robust solution for drowsiness mitigation. The results indicate that this sensor fusion approach is significantly more accurate than individual detection by module, allowing for the reliability necessary for real-world implementation. Furthermore, the system maintained a high degree of effectiveness even when tested under environmental stressors—such as low lighting and eyewear—that typically act as obstructions for traditional vision-based systems. Statistical testing validated the use of physical position-based modules. It was established that postural slumping and head nodding are distinct indicators that effectively differentiate between "Awake" and "Drowsy" states. With a mean latency of 473.88 ms, the system operates significantly faster than the typical human perception time, ensuring that safety interventions occur and the driver is reawakened a sufficient amount of time before a hazardous driving event occurs. Ultimately, by fusing the visual physical data into one functioning system, this project addresses the limitations of existing single-module monitors, offering a reliable tool to combat one of the leading causes of vehicular accidents, and potentially save more lives as well.