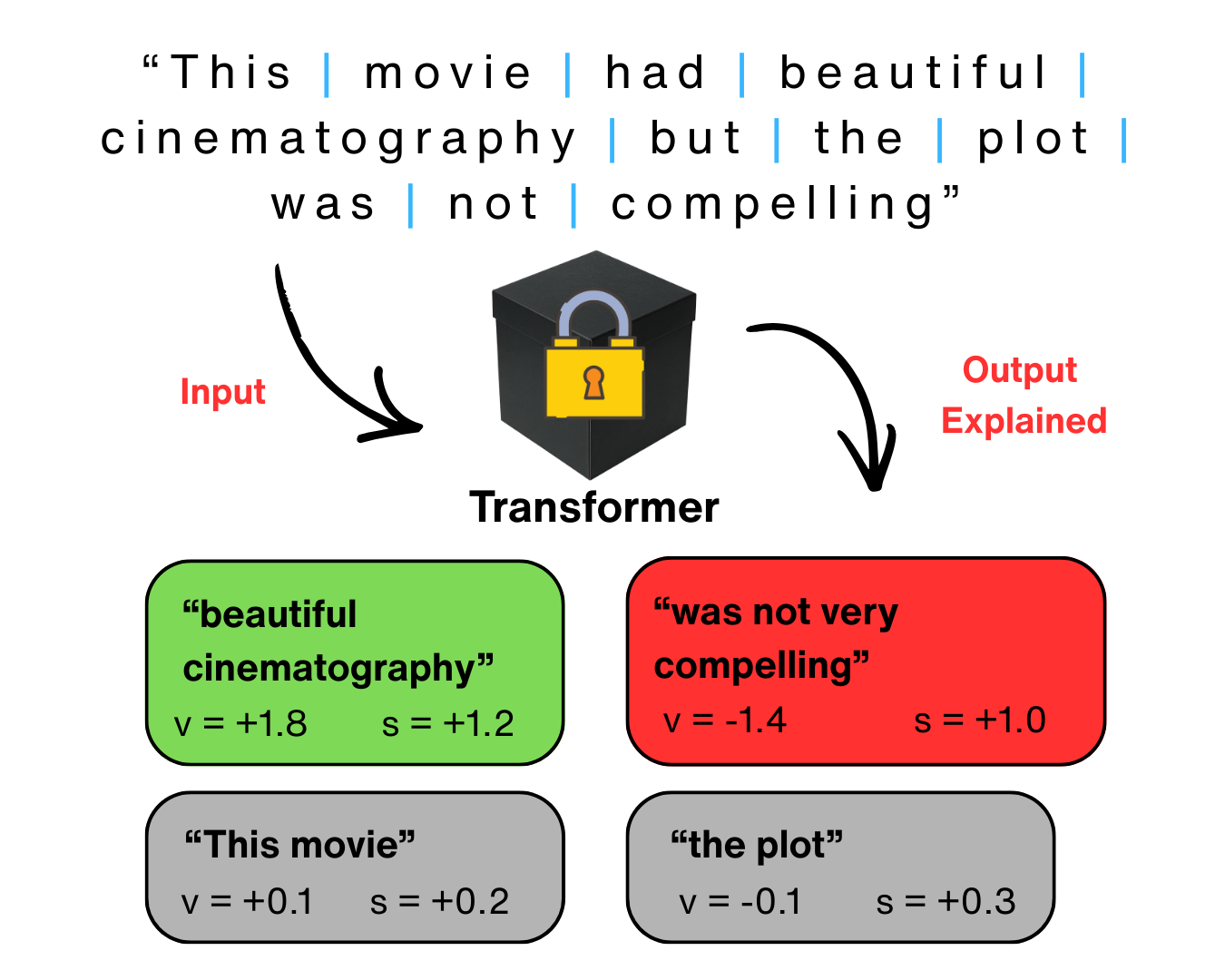
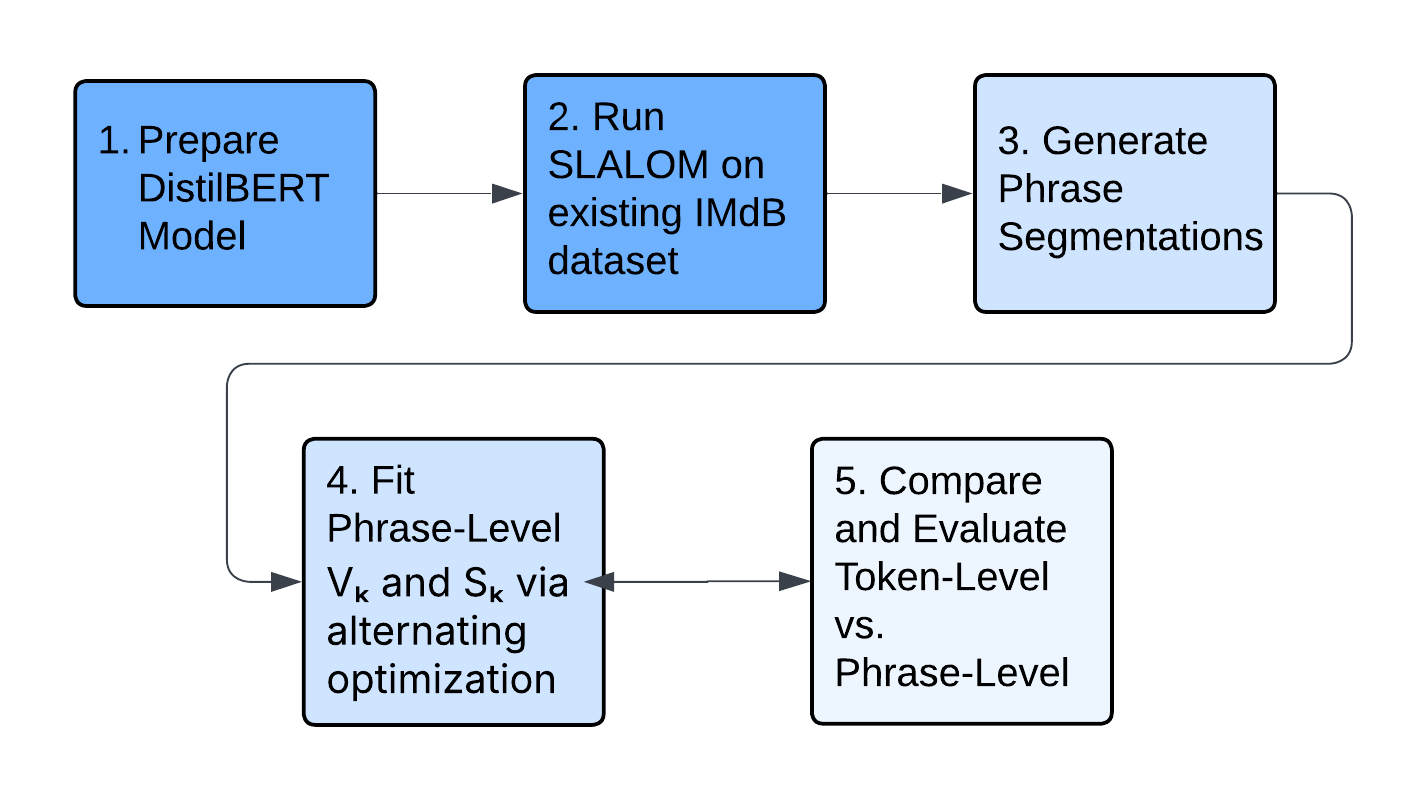
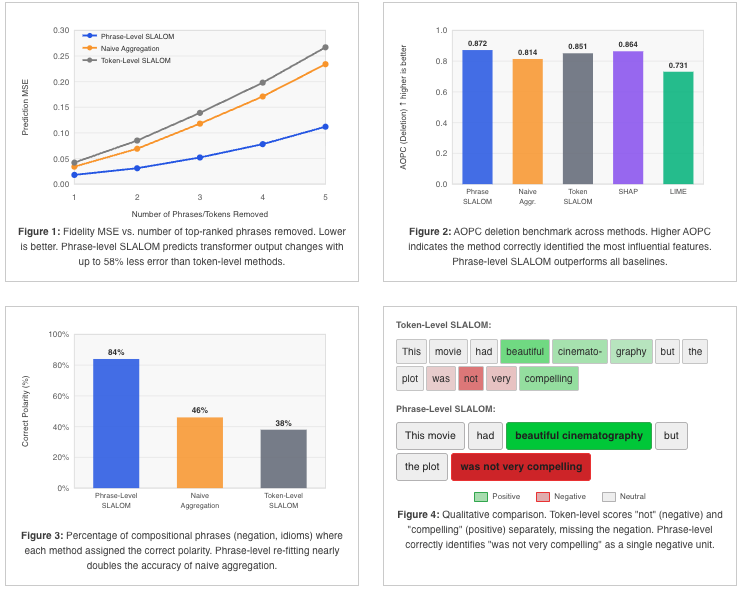
Transformer-based language models are increasingly deployed in high-stakes domains such as healthcare, law, and finance, yet they function as black boxes with no transparent reasoning for their outputs. Existing explainable AI methods attempt to address this by assigning importance scores to input features, but these methods assume that token contributions are independent. This assumption violates the softmax mechanism in transformer self-attention, which forces all token weights to sum to one. More recent approaches address this by fitting softmax-linked surrogate models that mirror the transformer’s architecture, but they operate only at the token level, missing phrase-level meaning in explanations. This project extended existing token-level explanation methods to phrases that are linguistically significant by defining a new phrase-level surrogate model. Input sentences were first segmented into phrases using dependency parsing. The model then assigned each phrase two scores: a value score representing the phrase’s absolute contribution to the output, and an importance score representing its relative weight among all other phrases. These scores were fitted by masking entire phrases from the input, observing how the transformer’s output changed, and then optimizing the scores to best predict those changes. On a sentiment classification dataset, the phrase-level model achieved 58% lower prediction error than the original token-level method and correctly identified the polarity of compositional phrases such as negation at 84% accuracy, which is nearly double that of summing the token-score outputs afterwards. These results demonstrate that phrase-level explanations more faithfully capture transformer behavior while producing outputs aligned with how humans naturally read and understand language.