STEM I
Course Description
STEM with Science and Technical Writing is an immersive course
into the world of STEM and scientific writing. This course consisted
of a 7-month-long Independent Research Project during the beginning
of the Junior Year where students researched and investigated a topic
of their choice to present at the final school-wide fair in February,
Assessing the Correlation Between Genetic Predisposition and
Health Insurance Rates
Overview
Health Insurance Companies may look at rates of genetic
mutations associated with higher risks of health conditions to
determine their premiums. To assess this possibility, the correlation
between the rates of 20 health conditions varying in their degree of
genetic heritability and health insurance rates was assessed.
Abstract
Health insurance is costly; Americans spent over $4.3 trillion
on healthcare expenses in 2020 alone, with over 85% through private
insurance providers (Center for Medicare and Medicaid Expenses,
2020). In 2010, The Patient Protection and Affordable Care Act
restricted health insurers' ability to deny and raise rates due to
pre-existing medical conditions. However, it was challenging to
enforce this section of the act because very little information is
known about how insurance providers determined their rates. This
study aimed to help resolve this knowledge gap by conducting a
correlative study between rates of genetic predisposition and health
insurance costs. Health insurance data was collected using public
marketplace databases, and information on rates of health conditions
was collected. Then, a Pearson Correlation was run on the two
datasets. The result was a Pearson Coefficient of r = 0.1198 for all
conditions and a statistic of r = 0.1464 among genetic conditions.
This result offered significant evidence that health insurance
companies used information on genetic predisposition to determine
their rates. This conclusion has significant implications for both
the healthcare and genetic testing industry. The information provided
by this study could be considered by clients interested in proceeding
with genetic testing, as being informed of the risk factors
associated with health insurance rates resulted in doing so.
Additionally, the study provided evidence for conducting a future
study using genetic mutation rates rather than incidence rates, which
would be used to rephrase legislation and terminology in the
Affordable Care Act.
Research Proposal
My full research proposal can be read here.
Phrase 1
What information do health insurance providers look at when
determining their rates?
Phrase 2
This study hypothesized that health insurance companies look at
genetic information to determine their rates.
Background
The Patient Protection and Affordable Care Act of 2010 (United
States, 2010), also commonly known as Obamacare, has been known to be
a rather controversial policy by many Americans. Nevertheless, it has
had many undeniable impacts on the medical industry and health
insurance providers. The subsection of the law regarding policy
relating to pre-existing health conditions is often considered to be
one of the most, if not the most impactful part of the act
(Kirzinger, 2022). The section states that no individual with a
pre-existing medical condition may be refused health insurance
because of their pre-existing medical condition. Although aspects of
these policies vary from state to state (Kominski, 2017), the
particular section mentioned above remains applicable on a national
level. However, insurance costs remain significantly expensive for
Americans across the nation, and these costs are only growing. In
2021, Americans spent about $4.3 trillion on health care expenses –
nearly 85% of these expenses being into Private Insurance Providers-
meaning the average American spends approximately $10,976 a year on
health insurance. Although the Affordable Care Act (ACA) aimed to
combat these costs, in response to the policies put into place by the
ACA, health insurance agencies have several methods to combat these
restrictive policies by taking advantage of loopholes in the
legislation. One such loophole exists due to the poor definition of
the phrase “refusing health insurance based on pre-existing medical
conditions” (United States, 2010). Because of the wording of this
section, although it is illegal for insurance agencies to directly
reject someone due to a pre-existing medical condition, they can
instead determine the probability that someone has an existing
medical condition or will be likely to develop one in the future
based on information on their demographics. This process will provide
the insurance agencies with a reasonable estimate of whether a
potential client has a pre-existing medical condition without needing
to directly evaluate if the potential client has a pre-existing
condition, thus making the process technically legal while having
practically identical results as if they violated the restriction
under the ACA.
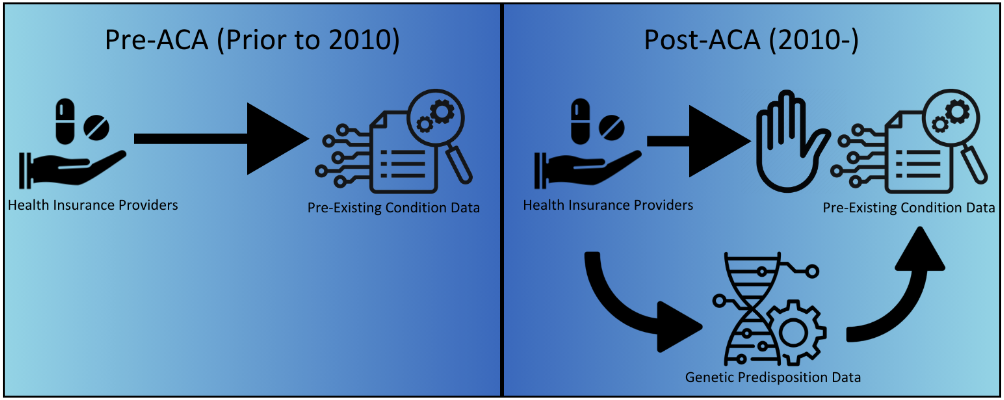
While this loophole has existed in the past, it is incredibly
more prominent today than ever due to the extensive development done
with genetic testing technology in recent decades (Rodriguez-Rincon
2022). Almost anyone can get their hands on a genetic test and for
much cheaper than it used to cost. Because of this outstanding influx
in the percentage of the population taking genetic testing, there is
now an incredibly large amount of data available to other genetic
testing providers. By taking a genetic test, an individual not only
gives their provider access to all the information relating to their
genome, but also information on notable statistics such as medical
conditions, medical history, age, sex, ethnicity, and geographical
location. All of this data is collected and inputted into databases.
While these databases have existed for a substantial amount of time,
they have not had nearly as much data available as they do now.
Because of this, the data available can be compiled into numerous
Genome-Wide Association Studies (GWAS) which are ever more accurate
and more developed than before.
Importantly, with the increase in data from GWAS available,
that information is now also accessible to health insurance agencies.
One important thing to note is that how insurers determine their
rates is generally very unknown. Because of this, health insurance
providers could be using the information provided by Genome-Wide
Association Studies to calculate their rates, and it would be unknown
to the public. Additionally, along with data from GWAS, insurers
likely compile other medical and genetic information such as through
screening panels, rates of conditions by demographic, and other
similar data, all of which are publicly available, to get a very
informative and statistically accurate understanding of how
predisposition to developing various conditions varies by
demographic. Nevertheless, this information is all related to the
rates of the genetic diseases themselves, which is what this study
used as data to research whether insurance agencies are performing
the previously described procedure. By taking the data from the rates
of several conditions and analyzing their correlation with health
insurance rates by geographic location, the level of correlation will
reveal the likelihood and extent to which insurance providers are
using the listed information to determine their rates.

Procedure
The health exchange data website, HIX Compare, has publicly
accessible reports on health plans by health insurance rate area, as
well as crosswalk datasets between health insurance rates and county.
This resource is updated annually, so this source was used to obtain
the average silver plan premium by county from 2014 to 2018. Data
obtained from this resource was compiled and stored in one large
spreadsheet.
Numerous reports, studies, and organizations have publicly
accessible data on rates of health conditions by county in the United
States. This study obtained data from numerous reports, such as the
National Cancer Institute’s State Cancer Profiles, which models the
incidence rates of cancers by county from 2016 to 2020. Similarly,
the Institute for Health Metrics and Evaluation provides a report on
the Mortality rates of diseases such as sexually transmitted
infections, diabetes and kidney disorders, and non-health related
injuries from 2000-2019. This report also used national atlases, such
as the Center for Disease Control and Prevention’s Interactive Atlas
of Heart Disease and Stroke in 2019 and the Centers for Medicare &
Medicaid Services annual reports from 2007-2018 on Chronic
Conditions. For a preliminary model, this system utilized annual
reports on Chronic Conditions as health condition datasets.
As mentioned above, the health insurance data collected was
displayed by the health insurance area, whereas the health condition
data was collected by county. To be able to map the data, a dataset
of rates by county had to be obtained. Conversely, the most accurate
Pearson Correlation depended upon having datasets of rates by health
insurance area. For these reasons, using the previously provided
crosswalk dataset, datasets were converted such that there was a
dataset of health insurance rates and health condition incidence
rates by county as well as by health insurance rate area. This
calculation was performed in Google Sheets using the “IF”,
“REGEXMATCH”, “XLOOKUP”, and other functions provided by the
software.
While there are other factors considered in health insurance
cost calculations, this study identified smoking and state-by-state
differences as two primary external factors from health rates as
contributors in health insurance price calculations. However, whether
the client is smoking is asked and considered in the premium
calculation process. Therefore, differences in rates of smoking by
county are not considered in premium calculation. Conversely,
state-by-state differences in policy, as well as the environment, are
not avoided by this; a great portion of how much one’s health
insurance costs depends upon their state rather than their county.
Therefore, intending to avoid this, this study correlated the amount
of change over the years in percent difference. By eliminating
smoking and state-by-state policies, this study created a more
accurate and predictive model. Finally, rather than investigating the
lowest policy by the state as many popular models do, this study
decided to utilize one health insurance plan to project how one plan
in particular changes as health condition incidence rates are
adjusted, choosing to only utilize Silver-Tiered Blue Cross Blue
Shield Plans, as it is one of the more popular providers, spanning
over 20 states. There are many advantages of this approach in
comparison to using the lowest rate. For one, it will eliminate the
variable that different health insurance providers are using
different data to determine their rates. This benefit in turn enables
the study to determine exactly what factors are used for each plan.
Conversely, a negative of this approach is in increasing the demand
for datasets included if the goal is to gain an understanding of all
health insurers. However, this model functions solely as a more
preliminary study, so it does not necessarily require this. See below
for maps of the data obtained from this process created using
Datawrapper.
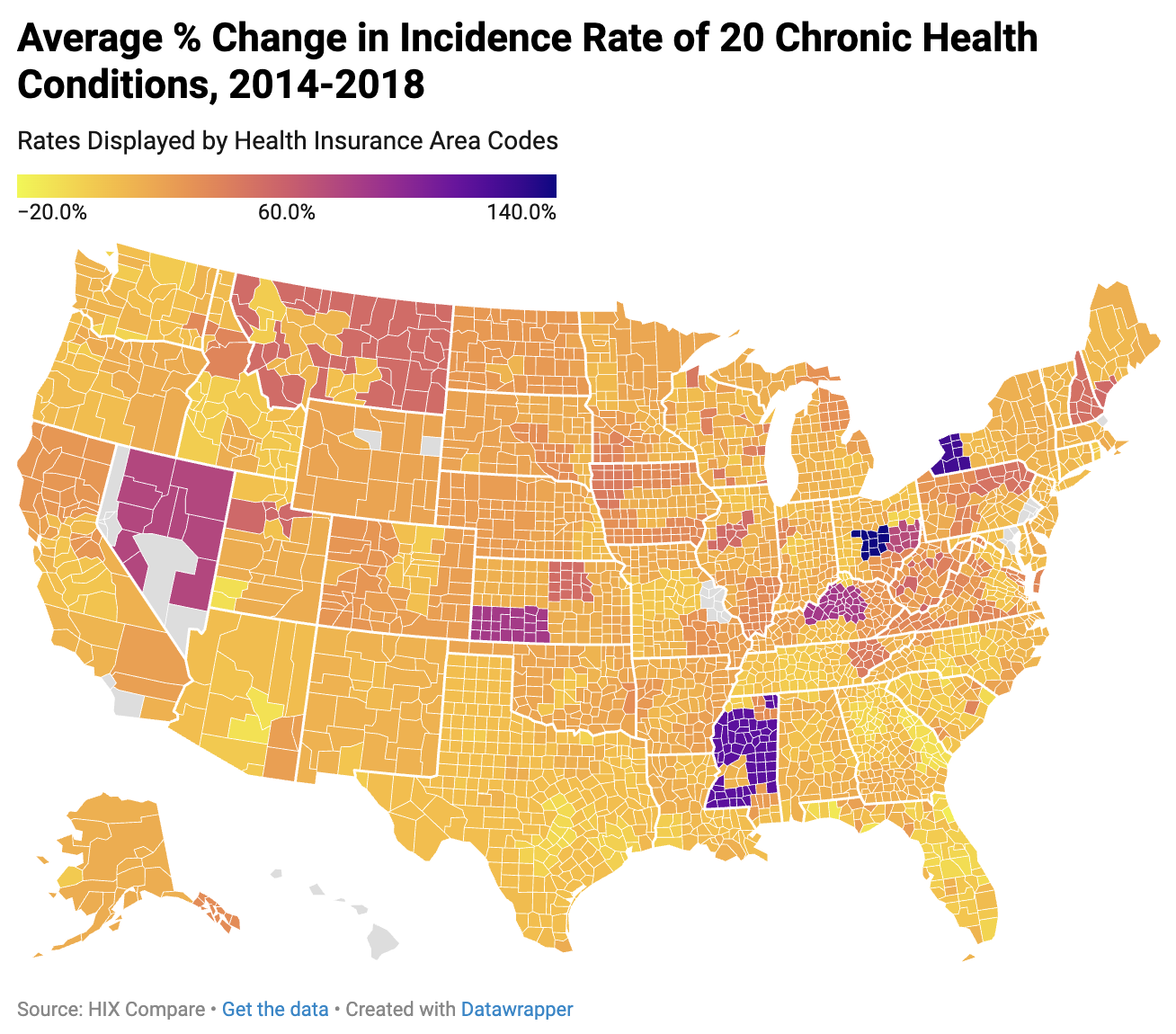
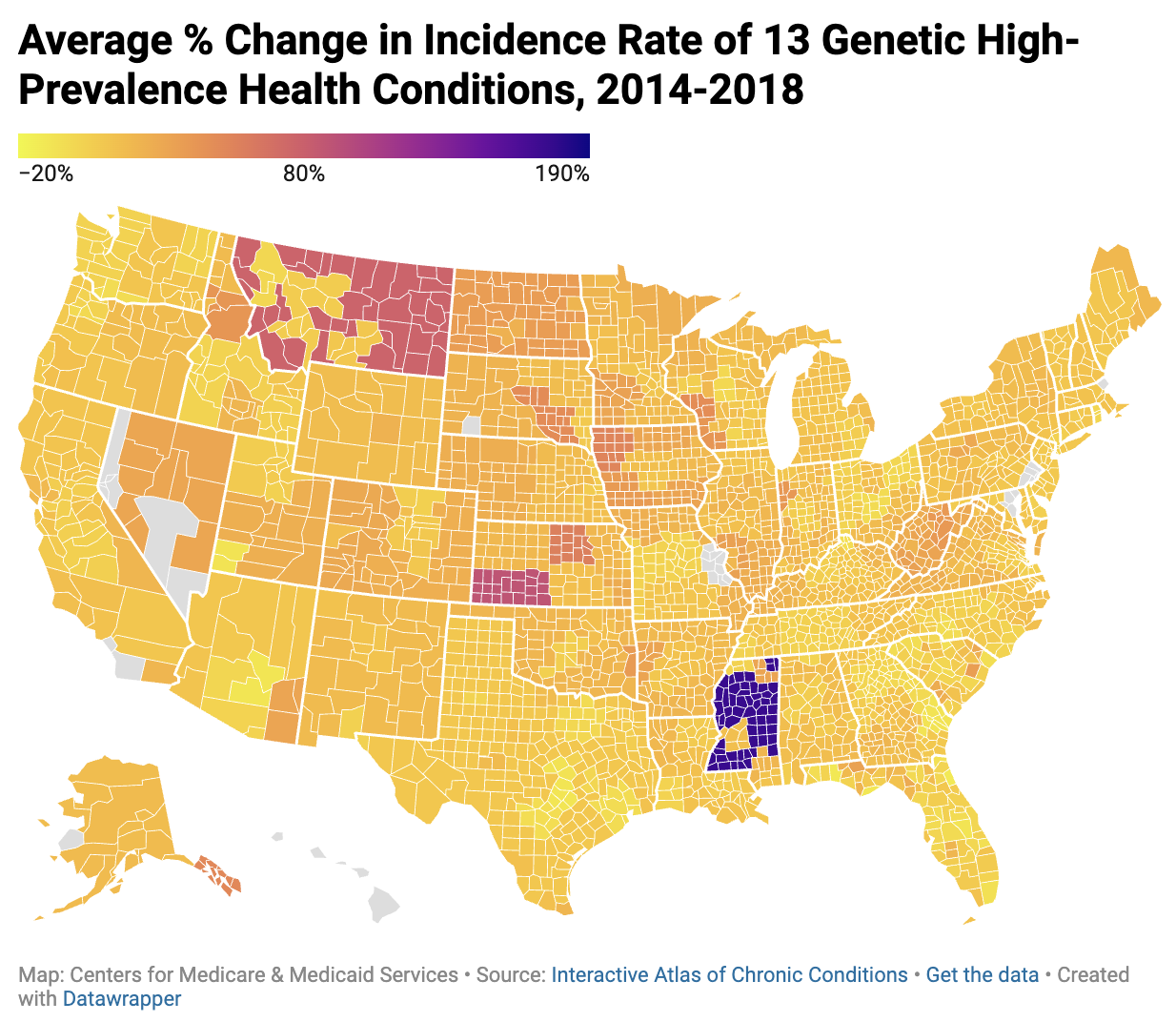
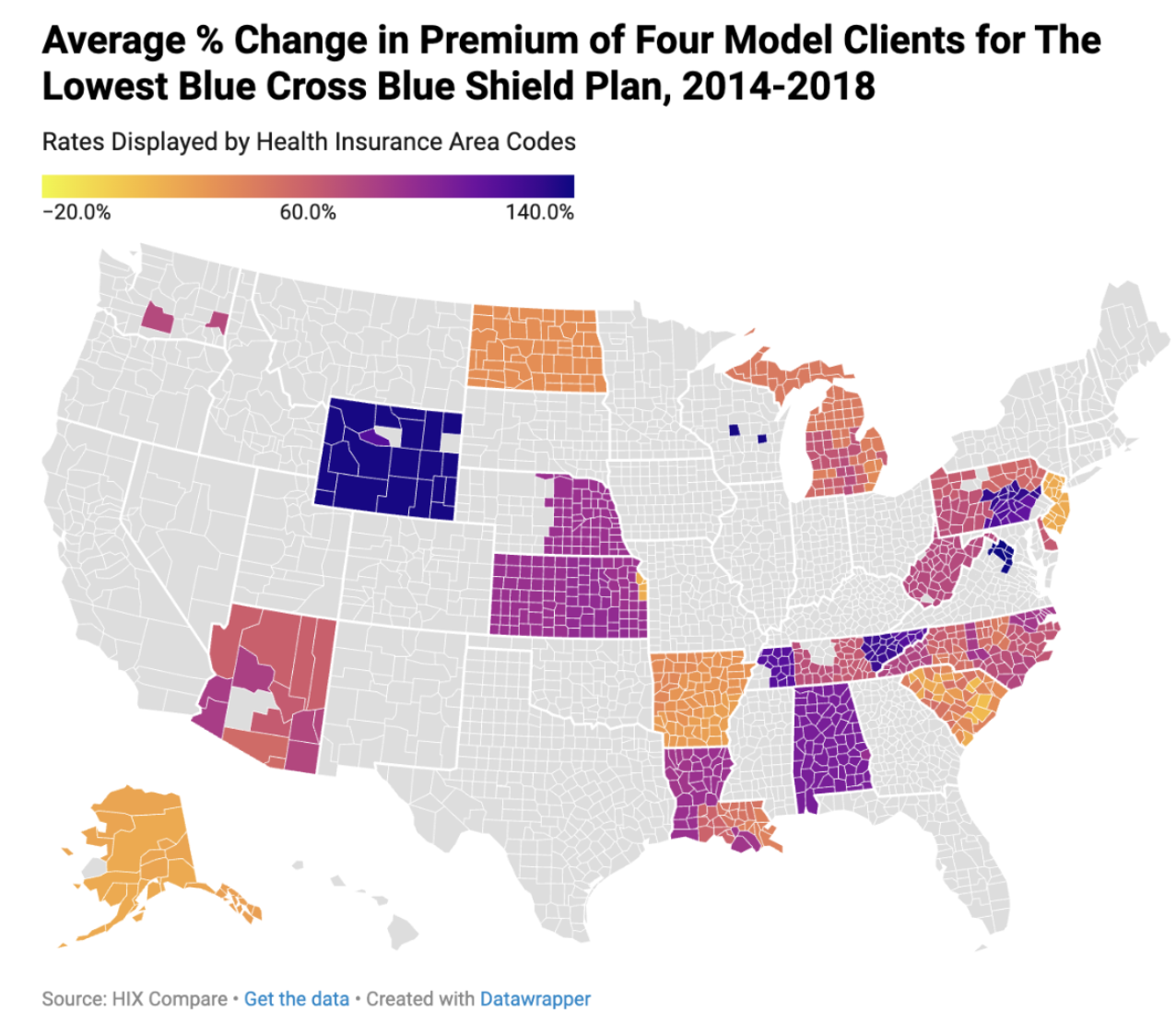
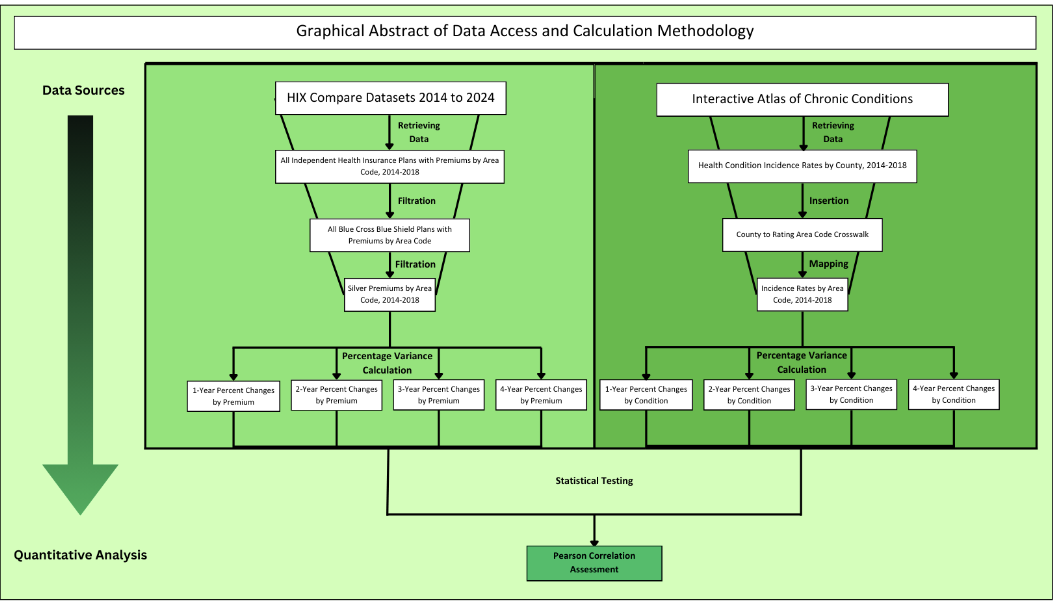
Analysis
A Pearson Correlation Assessment was used as a statistical test
for this study. A Pearson correlation is a form of a linear
regression model that assesses the degree to which two sets have a
correlation with each other, reflected by a coefficient (R) from -1
to 1. A Pearson Correlation was run for each health condition in
relation to the average health insurance premium by county.
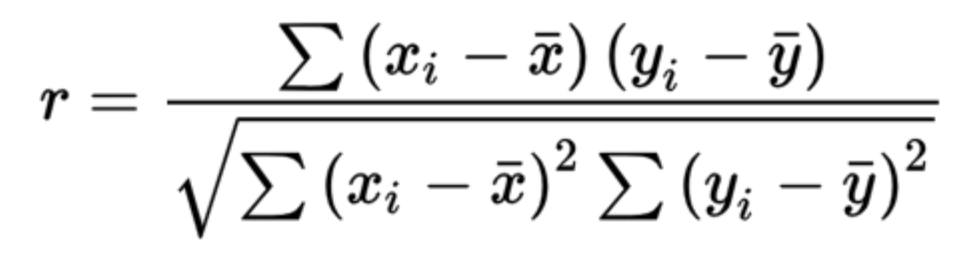
Based on the calculations run above, this study found an
average Pearson coefficient value of r = 0.1198 (See Table 1 for full
data). However, of the 13 conditions chosen with high prevalence and
genetic mutations associated with their prevalence, there was a
Pearson coefficient value of r = 0.1464.
Discussion
While it is known that a Pearson value less than or equal to
0.5 is not statistically significant evidence for a correlation, this
study is rather a comparison of Pearson coefficients. Given that
there is a larger correlation coefficient for one health condition
with health insurance premiums than another, there will be a greater
overall correlation between the first two than the second.
As this model analyzed is a preliminary version, there are
several limitations to the design that should be taken into account.
For one, the amount of data that this study was able to compile for
statistical testing became exponentially limited as mapping health
insurance plans was undergone. To avoid this, this model may be
expanded into considering additional plans rather than one, along
with adding more health condition incidence rates to create a more
informed final result.
This study expands upon several preexisting studies to go about
answering its central question of “How do health insurance companies
determine their rates?” One study which a great portion of the idea
for this project stems from is “Assessing the Impact of Developments
in Genetic Testing on Insurers’ Risk Exposure” by Rodriguez-Rincón
et. al., 2022. As a study investigating a very closely related
problem from the perspective of insurers, it had a significant impact
on the development of this study.
Following expanding this model for more insurance plans and/or
health conditions, if there is sufficient preliminary evidence
gathered from this initial model, the results of this study could be
used as significant evidence for running a similar study using
genetic predisposition rates.
Conclusion
The goal of this study was to identify differences and
similarities among health conditions in their correlation with health
insurance rates by county. By collecting and normalizing data, and
then running a Pearson Correlation on each dataset, it was observed
that there were higher correlation values among genetic conditions
than non-genetic ones. Following this study, there is sufficient
evidence promoting further research of this trend using genetic
predisposition data.