STEM I
This course focuses on developing science and
research skills and working on a long-term stem project for the
February school science fair. The class is taught by Dr. Crowthers, the STEM Overlord, who provides guidance in writing about and carrying out our project ideas.
Multilingual Dementia Detection through Deep Learning
This project aimed to create a model based on a large language model (BERT) that could diagnose dementia and/or Alzheimer's disease using generated transcriptions of raw speech. The end project was able to produce an English model with a maximum accuracy of 79% in addition to a multilingual model and a model trained in another language.
Abstract
Graphical Abstract
Alzheimer's disease, a subset of dementia, is a cognitive illness that will affect 152 million people by 2050. Despite its effects, only 50% of people with dementia have received a diagnosis (Shinkawa et al., 2018). Alternative diagnosis methods must be pursued to make diagnoses more accessible. This project aims to expand on the progress made by prior research by applying speech-based dementia detection models through a multilingual lens to provide a low cost, globally accessible method of detection. Current research into such models often focuses on English, which is a gap in the field (Perez-Toro et al., 2023). The model/s used combined transcription with binary classification by a large language model. Various configurations were used including monolingual and bilingual large language models and various transcription models. There is potential for such models to become widely used methods that can help steer people towards diagnoses through access to MRIs or other detection technologies. Such models could be implemented globally to inform people of the risk of developing cognitive illness and allow them access to a reliable detection method. Some possible implementations could be as a part of an app or as a short portion of a doctor’s appointment, which would make a model easily accessible to a wide variety of people.
Engineering Need
Engineering Goal
The goal of this project is to create a deep learning algorithm that can detect Alzheimer’s Disease across multiple languages without the need for extensive training data from patients speaking a language.
Alzheimer’s Disease and dementia are increasingly large problems for our growing population, yet they often remain undiagnosed, and speech research is largely centered around English.
Background
Alzheimer’s disease, a subset of dementia, causes a decrease in cognitive ability, decreasing the patient’s ability to perform common tasks such as accessing memories and communicating with others. Constant work is done to provide a sound cure for Alzheimer’s, yet these cures are only as effective as the methods used to detect Alzheimer’s and dementia in early stages. With the current methods of detection only finding 50% of those with the illness (Shinkawa et al., 2018), more research needs to be done so that the expected 150 million Dementia patients by 2050 will have longer, happier lives.
Current Alzheimer’s detection methods typically are based on the detection of biomarkers known to be associated with the disease. MRI and PET scans are some of the more common testing methods (Yang et al., 2022). While extremely accurate, the manpower and cost involved in carrying out such tests make them hard to access, especially in locations where healthcare systems are not strong. Another testing method is the collection of cerebrospinal fluid. Whilst cheaper, this method is very invasive and thus undesirable for the patient (Yang et al., 2022).
Machine learning models that can detect Alzheimer’s through speech have also been explored. This method is much cheaper to scale, but the high level of data collection required has restricted this method in many studies to being used in one language, which is often English (Pérez-Toro et al., 2023). In English alone, databases containing Alzheimer’s or Dementia patients and healthy controls need to be ethically collected to perform these tests, with enough data for models to be accurate. The high bar of entry is especially detrimental to smaller communities that may share a tribal, regional, or uncommon language. 6909 languages exist currently, making training an individual model for each language a lofty goal (Anderson, n.d.). A model could be developed to incorporate universal features of similar languages, or of any language with training data, to provide tools for diagnosis in a more diverse band of languages.

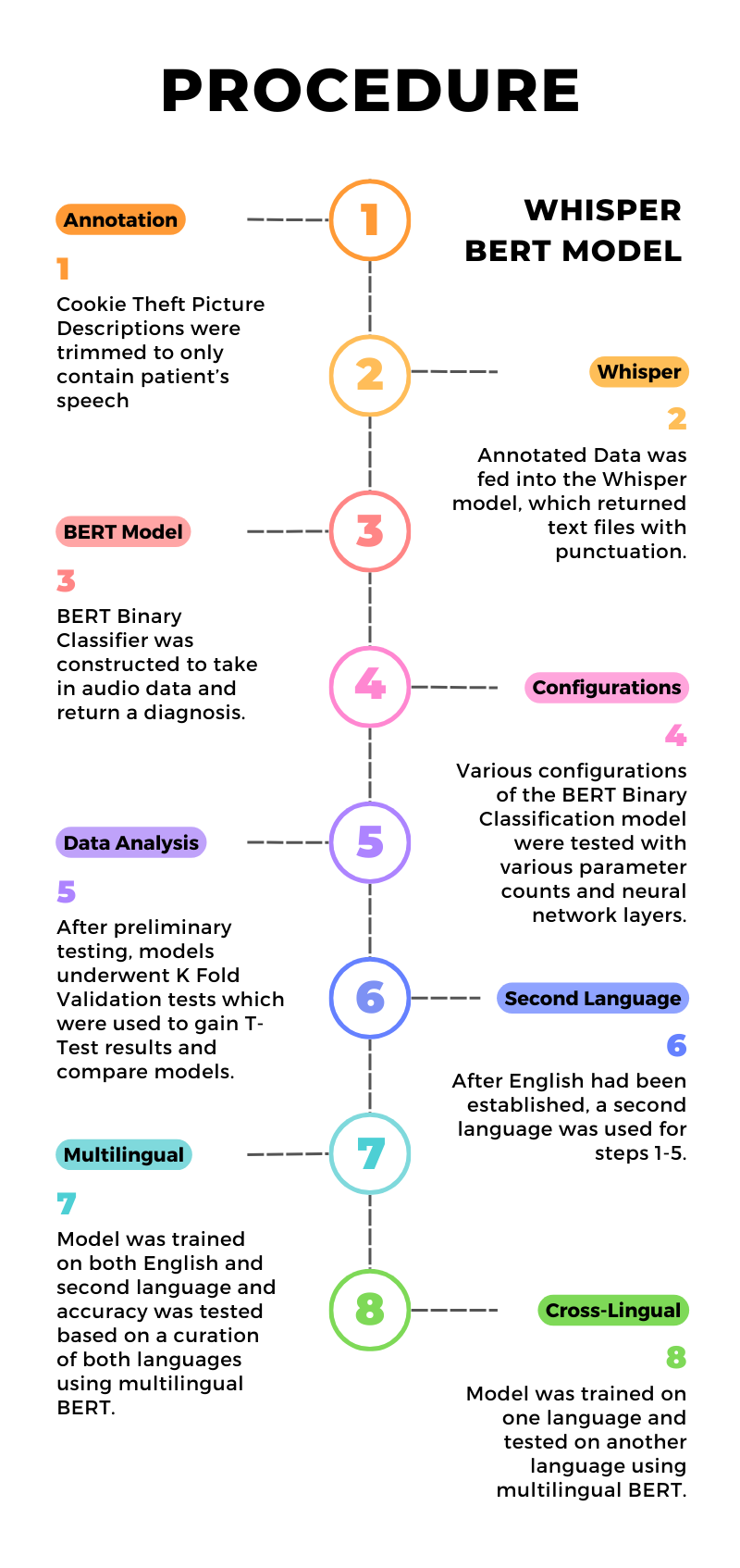
Procedure
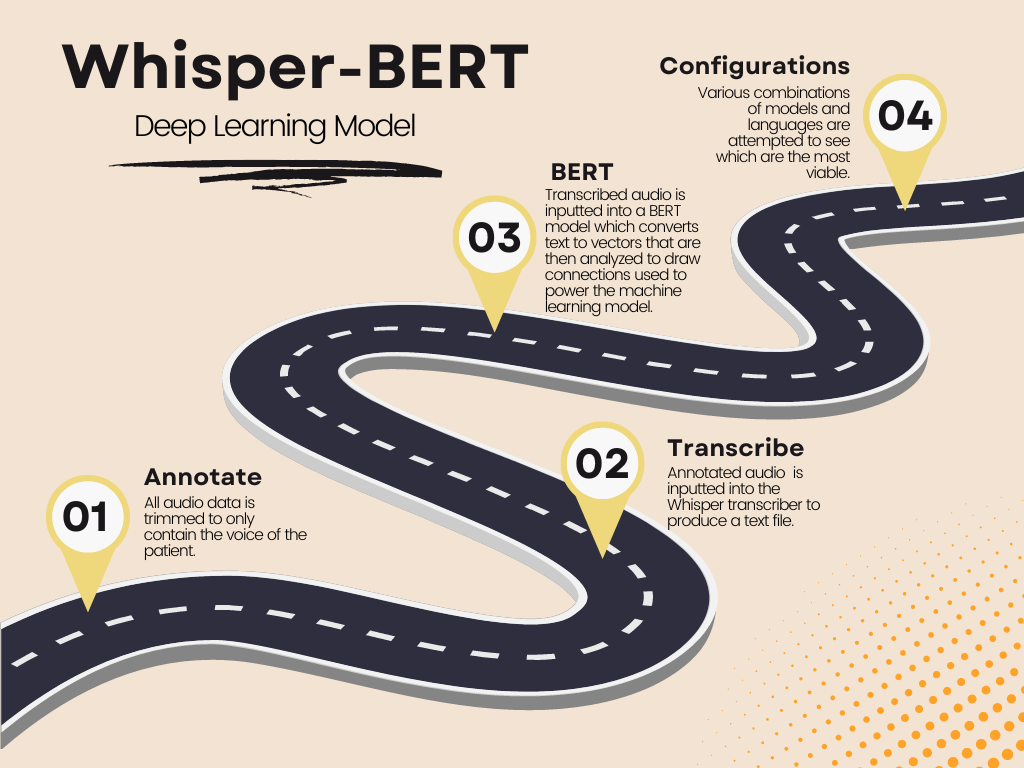
The processing of the data was segmented into three different sections: filtering, transcription, and detection. The filtering process involved sorting audio data in Audacity so that the only audio left is pure audio of the patient speaking. The sorting process could only remove blank space (no one talking) at the end or beginning of the recording. Any audio cut out was only of speakers that were not the primary patient. These portions cut would only contain another person, such as an interviewer, talking. In this step, some recordings were flagged due to extensive background noise that made the transcription step inaccurate. This could be noticed if the whisper transcription contained more than one line of text not spoken at the same time as the primary speaker. Once the audio had been processed, it was inputted into the Whisper model, which would return text in a text file for each recording. The text would be pasted into a csv file so that the BERT model could access it easily. After all the data was compiled in a csv file and labelled as a 1 for dementia or a 0 for control, the BERT model was compiled and ran through a python script. The script first converts the text to vectors, then compares the vectors of various speech samples to come to a conclusion as to patterns that can help detect dementia Various Configurations of languages were ran through this pipeline, as well as different versions of BERT. For example, both languages were trained on the English BERT and results were returned. The same training was also done in a multilingual BERT. Additionally, training the BERT models on solely one language but testing on multiple was done.
Figures
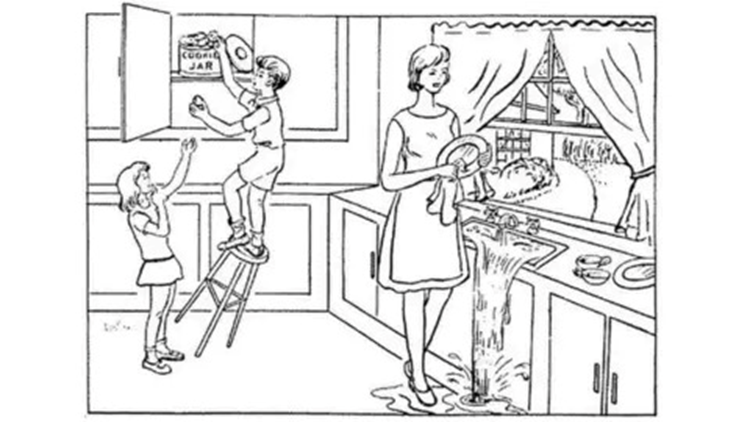
Figure 1: The Cookie Theft Picture Description task from the Boston Diagnostic Aphasia Examination
Figure 2: The number of control and dementia recordings used from the Pitt Corpus to train the English Model
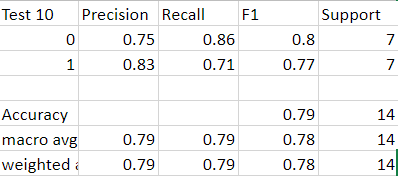
Figure 3: The maximum accuracy of the most accurate English model
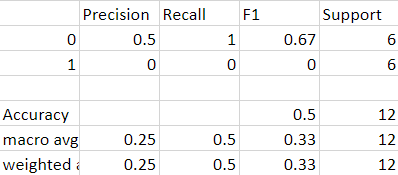
Figure 4: The maximum accuracy of the first iteration of the English model
Analysis
When run using an English cased BERT with 768 variable parameters, an accuracy of 50% was achieved on the initial model. This data was collected from a testing set of 8 samples combined with a training set of 30 samples. As shown in Figure 1, the current data showed no trends, with the model splitting evenly between choosing the control and the Dementia patients. The ratio of true positives to all positive predictions was 50%, like the ratios of true positives to true positives and false negatives and the f1 score. No data has been collected yet on using a second language.
The second model used processed data as 2D arrays from the sequence output of the text when put into the BERT encoder. Various versions including those that had 1024, 512, and 768 parameters per word, all returned 50% accuracy in which all the test points were given the same diagnosis.
When run using an English uncased BERT with 768 parameters, an accuracy of 71% was achieved. This data was collected from a testing set of 14 samples combined with a training set of 146 samples. 80% of all dementia patients were predicted correctly, in addition to 67% of non-dementia patients.
The fourth model used English uncased BERT with 256 parameters and returned a maximum accuracy of 79%. The accuracy of the positive results was 83% with a support of 7 dementia transcripts and 7 control transcripts. With K Fold Validation of k=10, an average of 64% accuracy was achieved.
Discussion
4.1 Project Goal
The goal for this project was to create an effective multilingual Dementia detection model. This model would possess strong accuracy in English and carry over some of that accuracy into another language. Cookie Theft picture description data from English and another language were used in the model in multiple configurations to collect data. The model's primary configuration was a combination of a transcription software and a large language model, in this case Whisper and BERT.
4.2 Challenges
There were several challenges with creating this model. One of the most significant difficulties was trimming the data so that the model was only analyzing speech made by a patient. This challenge was dealt with by manually trimming the data. Also, a lack of accuracy in the first iteration of this model was improved by analyzing more data and using a stronger, more computationally intensive BERT model. Furthermore, the Turing computing cluster at WPI was used so that data could be processed faster and with greater strength. A personal desktop computer did not have enough RAM to process the data, but the Turing cluster’s 4.5 TB of RAM and NVIDIA A100 GPUs were more than sufficient for the computing needs of this project.
The BERT model used also produced some challenges. Due to the various configurations of BERT including versions that were cased, uncased, and had different lengths of vectors per word, it took much time to find a model that could produce strong results. Some models could consume as much as 70 GB of VRAM, which made it difficult to run both locally and through a computing cluster. The use of a computing cluster also delayed the results of the project, as the model had to wait in the queue before it was processed, even if the code contained errors or was ineffective. The iteration trained on the computing cluster was not effective, which led to advancements to the first model being made instead to create a second model that could run locally. This local model could train in 1 minute, which makes its current accuracy of 71% promising. With a stronger model, these numbers could be expanded to achieve over 80% accuracy in English.
This research differs from other research as the Whisper transcription software has not been tested much through Alzheimer's detection models. This provides new data that could be used to determine what type of model could be implemented and distributed to patients in the future. Additionally, testing across languages is an application that has not been explored significantly, especially when using a transcription and classifier combination model.
Much like past studies such as those of Zhu et al (2021), the models trained were proof that such a model could be feasible in the future. Although accuracies never exceeded 90%, these models prove as baselines for other models to achieve accuracy that could be satisfactory for a clinical level.
4.3 Future Research
In the future, more iterations of this model could be tested to achieve potentially higher accuracy. The current model trains at a rapid rate, which could be adjusted to account for access to stronger GPUs to compute text in a more detailed, complex method. Additionally, applications of such a model could be explored. Through a mobile or web application, such a model could be provided to many people, letting them gain insight into whether they may develop dementia in the future and how to address those risks.
Conclusion
5.1 Summary
With the goal of the creation of a multilingual dementia detection model through speech in mind, several models were developed and iterated upon to discover which would be the most effective. Various sources of computing were used, including a desktop computer and the WPI Turing High Power Computing Cluster. As testing of the models continued, local computing ended up being used the most due to its flexibility.
The English model obtained a maximum of 79% testing accuracy after spending approximately 1.3 seconds per epoch out of 30 total. This accuracy is promising, as it shows that such a model can be expanded upon to create a model that could diagnose with accuracy beyond that of previous studies. Although much progress could be made to improve this model, it has been shown that such a model can be created, despite the similarity of the scenes that patients talk about in the Cookie Theft Picture Description. Cognitive aspects of speech are vital to this process as well, shown using Whisper as opposed to alternatives such as wav2vec, which do not include punctuation.
Such a model could have significant global impact through various mediums, including analysis of such speech tasks during doctor's appointments, phone conversations, or through tasks on an app. Analysis of speech only requires access to computing resources, which can be accessed from many locations in the current age.
Through progress in deep learning, early diagnosis of patients with dementia and Alzheimer's disease can be possible whilst saving families significant amounts of money and freeing access to other detection methodologies.
References
Poster