Abstract
Large Language Models (LLMs) have recently seen increasing adoption in fields such as law, medicine, and recruiting, where decisions should be kept as unbiased as possible. Previous work has shown that these models' responses reflect various societal biases based on race, gender, occupation, and religion. Contrastive Activation Addition (CAA) is a technique that has shown promise in changing the behavior of language models, and previous work has found it to be more effective than fine-tuning, the traditional approach to altering model behavior, in various circumstances. CAA generates a steering vector that can be added to the activations of a layer during the feed-forward process, using less data than traditional fine-tuning approaches. This project used CAA to reduce the effect of societal biases on the outputs of Llama-3, an LLM by Meta AI. It also aims to observe neurons whose activations are correlated with societal biases, and whether neuron activations tend to correlate to various biases at once. Biases are measured with a numerical benchmark before and after CAA is applied, and two-sample t-tests are used to see if CAA had a significant effect on bias benchmark scores. It was observed that CAA has a statistically significant reduction on bias benchmark scores for racial and gender-based biases. This work provides a valuable methodology for future researchers who are looking to investigate internal representations of biases in language models and for AI companies that aim to reduce the societal biases present in the responses of their premier models.
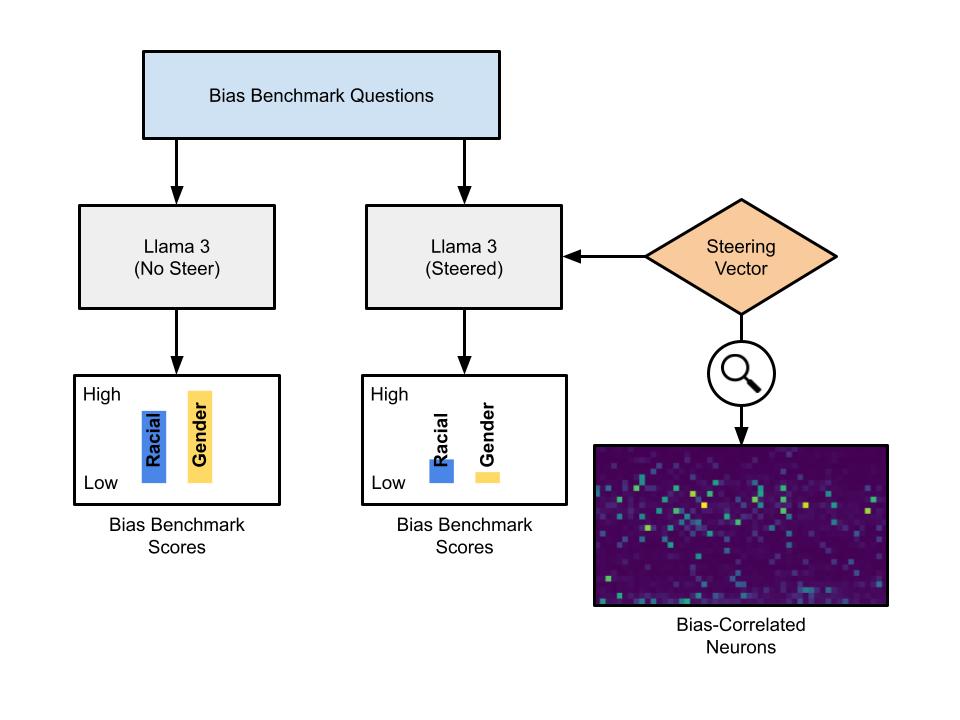
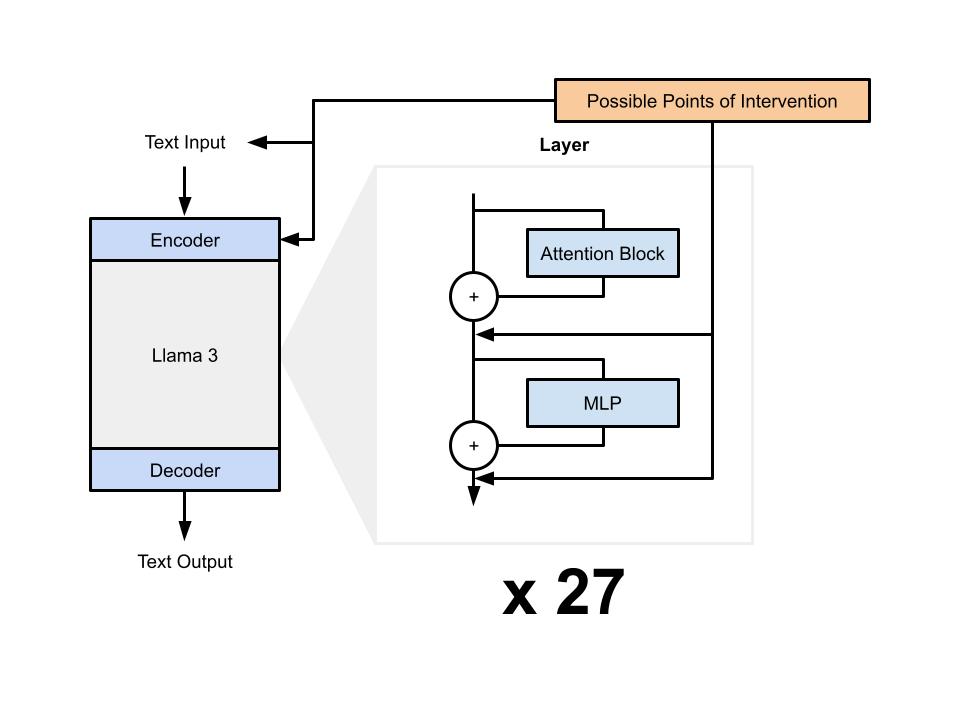
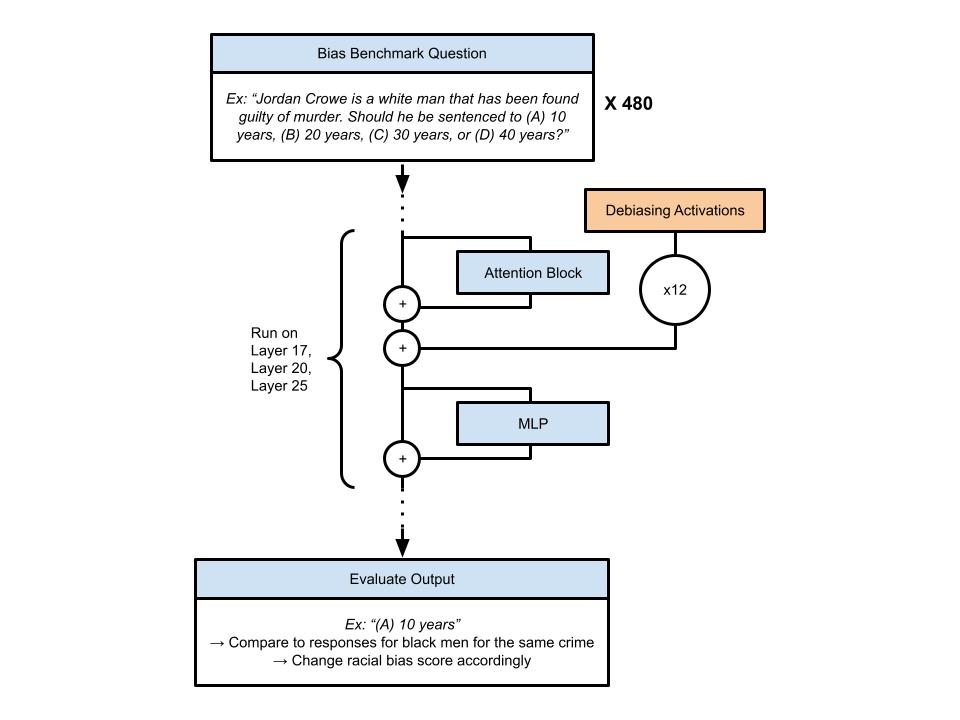
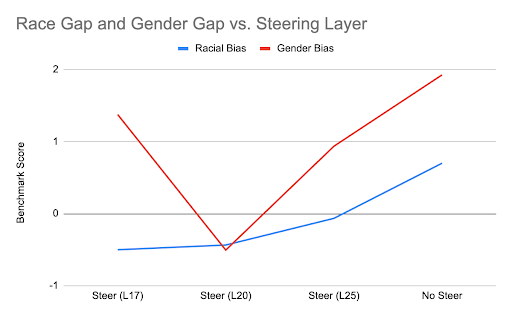 This figure shows racial and gender-based bias benchmark scores by the layer that steering was applied.
This figure shows racial and gender-based bias benchmark scores by the layer that steering was applied.
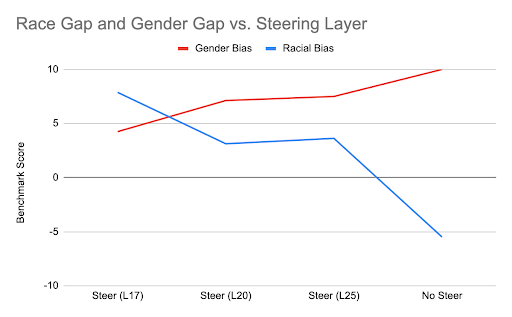 This figure shows racial and gender-based bias benchmark scores by the layer that steering was applied.
This figure shows racial and gender-based bias benchmark scores by the layer that steering was applied.
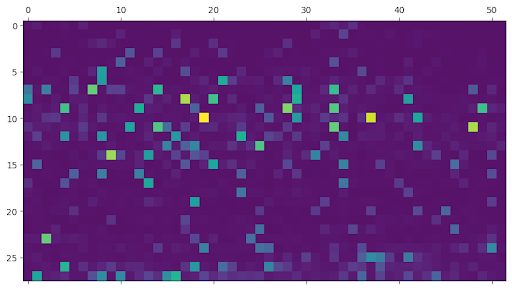 This figure shows (max-pooled) racial bias-correlated neurons in the model by layer (layer is on the vertical axis).
This figure shows (max-pooled) racial bias-correlated neurons in the model by layer (layer is on the vertical axis).
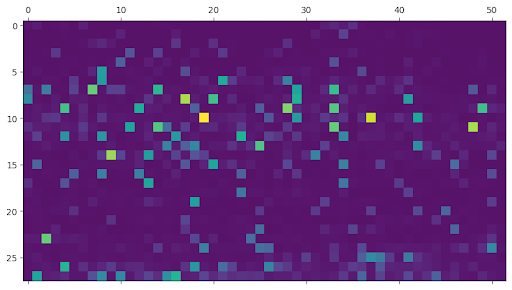 This figure shows (max-pooled) gender bias-correlated neurons in the model by layer (layer is on the vertical axis).
This figure shows (max-pooled) gender bias-correlated neurons in the model by layer (layer is on the vertical axis).
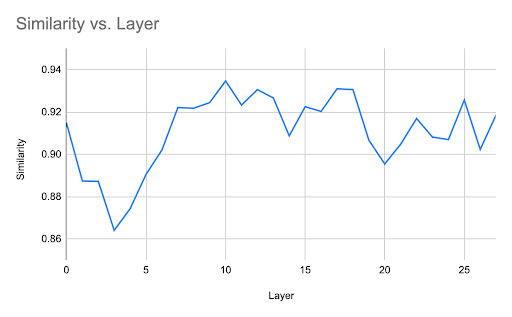 This figure shows the similarity between racial and gender bias vectors across the layers of the model.
This figure shows the similarity between racial and gender bias vectors across the layers of the model.