
With the motivation of improving the quality of speaker embeddings, we have collected and are releasing for academic use the BookTubeSpeech dataset, which contains many thousands of unique speakers. Audio samples from BookTubeSpeech are extracted from BookTube videos - videos where people share their opinions on books - from YouTube. The dataset can be used for applications such as speaker verification, speaker recognition, and speaker diarization. In our ICASSP'20 paper, we showed that this dataset, when combined with VoxCeleb2, yields a substantial improvement in the speaker embeddings for speaker verification when tested on LibriSpeech, compared to a model trained on only VoxCeleb2.
BookTubeSpeech
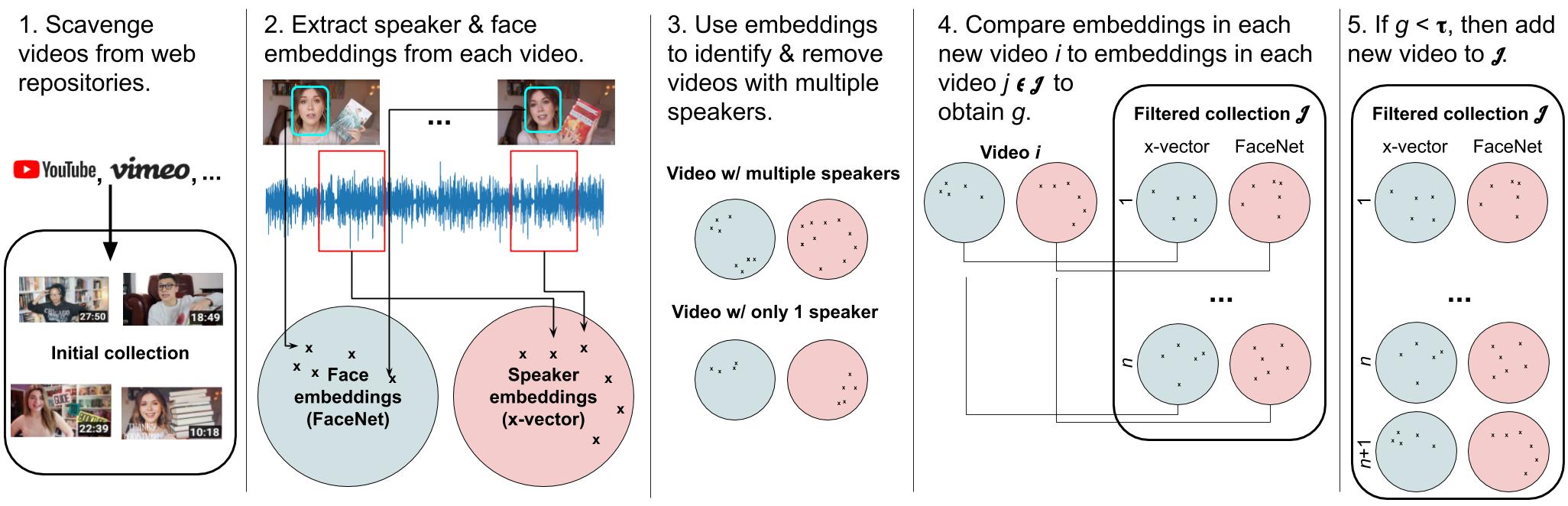
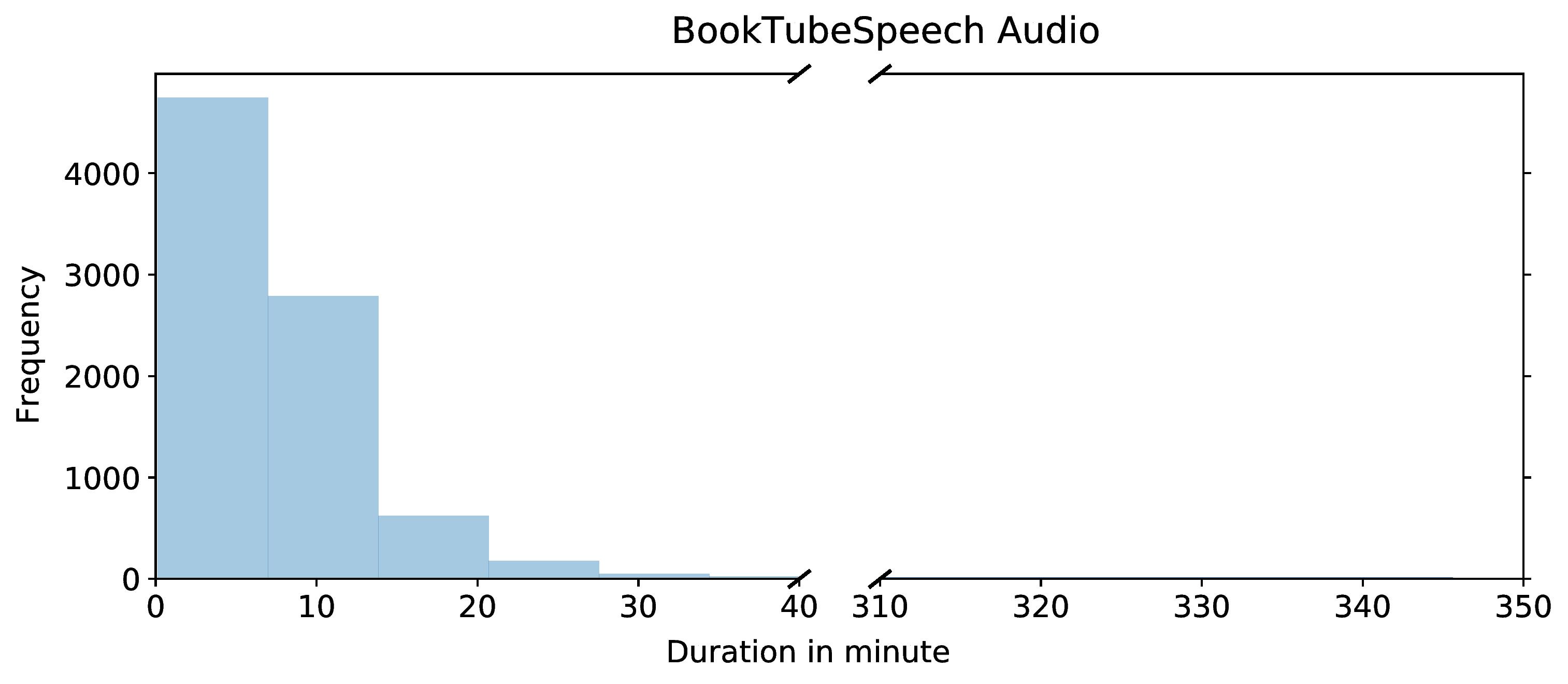
To collect BookTubeSpeech automatically, we followed the pipeline shown above. We pruned our initial set of 38,707 BookTube videos down to a collection of 8,450 videos with distinct speakers. The average duration of all the files is 7.74 minutes. Most videos are less than 20 minutes; see histogram below.
Downloads
Below we provide the URLs for the BookTubeSpeech videos -- both the entire set of videos we initially downloaded, as well as the pruned version that contains distinct speakers.
| Name | Link |
| Pruned BookTubeSpeech YouTube IDs (8,450 videos, whereby each video belongs to a distinct speaker) | here |
| All BookTube URLs (38,707 videos in total, whereby multiple videos may come from the same speaker) | here |
Each file contains a list of YouTube IDs. For instance, to access the video with YouTube ID b3Wz0dSExv0, simply construct the URL: https://www.youtube.com/watch?v=b3Wz0dSExv0.
The .wav files for the 8,450 pruned BookTubeSpeech videos are also available for download, but request must be explicitly granted. Please email mnpham@wpi.edu for access.
Publication
Please cite the following paper if you make use of the dataset.

The BookTubeSpeech dataset is available to download for commercial/research purposes under a Creative Commons Attribution 4.0 International License.
Acknowledgements
This material is based on work supported by NSF Cyberlearning grants 1822768 and 1551594.