# jemdoc: menu{MENU}{index.html}, showsource
= Research: Overview
My research goal is to integrate *control theory, formal methods, and
game theory* to construct **robust and provably correct** autonomous
robots and cyber-physical systems with a holistic dynamic and
epistemic model of the world.
Particularly, our research group is interested in control
synthesis under complex mission specifications specified in [https://en.wikipedia.org/wiki/Temporal_logic *temporal
logic*] --- A subset of second-order logic. Interested readers are
encouraged to find out in [http://www.runtime-verification.org/course09/lecture6/lecture6.pdf this lecture note] to know where this language lies in the
[https://en.wikipedia.org/wiki/Chomsky_hierarchy Chomsky's hierarchy]. A subset of temporal logic formulas used for autonomous
driving can be found in [http://www.cds.caltech.edu/~murray/preprints/wtm12-us_s.pdf this paper] or [img/self_driving_ltl.pdf here] for a quick preview.
With more expressive power, the challenge is to ensure correctness in
control design for systems with respect to such specifications,
especially in environments that are *uncertain and dynamic*,
such as tactical planning in adversarial environments, human-robot
collaborative teaming.
= Ongoing projects:
== Sequential Hypergames: Modeling, Specification, and Learning-based Synthesis of Deceptive Policies (SHADOW)
~~~
{}{img_left}{img/summary_shadow.jpg}{alt text}{400}{300}
In collaboration with [https://www.ssci.com/ Scientific Systems Co Inc]
SSCI PI: [https://scholar.google.com/citations?user=8VDAxFkAAAAJ&hl=en Dr. Mitchell Colby]
WPI PI: Dr. Jie Fu
This objective of this project is to develop models and methods for
intelligent decision-making that leverage information for strategic
advantages. The project introduces a variant of hypergames to capture
temporally evolving strategic interactions in games with asymmetric
information and complex mission specifications. We propose to
integrate learning to predict the evolution of perception of the
opponent about the other players’ payoffs. The integration of
prediction and game-theoretic planning will serve the fundation to
optimal policy synthesis methods, employing multiple deceptive
mechanisms.
Research aims
. Synthesis of Deceptive Optimal Strategies in a conflict.
.. Payoff manipulation with temporal logic task specifications.
.. Reactive synthesis with action deception.
. Intent prediction with Bayesian Inference and Inverse Reinforcement Learning.
.. Inverse Reinforcement Learning (IRL) with limited data.
.. Online prediction of counter-policy and proactive game-theoretic planning.
~~~
Related Publications:
- Abhishek N. Kulkarni, Jie Fu, "Opportunistic Synthesis in Reactive Games under Information Asymmetry", [https://arxiv.org/abs/1906.05847v1 arXiv:1906.05847v1] , /IEEE Conference on Decision and Control/, accepted, 2019.
Sponsor:
~~~
{}{img_left}{img/darpa_logo.jpg}{alt text}{150}{150}
~~~
== Intelligent Soft Robot Mobility in the Real World
PI: [https://www.wpi.edu/people/faculty/cdonal Dr. Cagdas Denizel Onal]
Co-PI: Dr. Jie Fu
The goal of this project is the creation of soft, snake-like robots that can navigate through real environments with confined spaces, fragile objects, clutter, rough and/or granular surfaces. The project includes three research thrusts, namely modular mechanical design of a segmented snake robot, low-level algorithms for the robot to execute simple functional motion primitives, and high-level planning algorithms to construct appropriate sequences of motion primitives in order to meet mission objectives. Because they can deform in response to their environment, soft robots can adapt to unexpected circumstances more robustly than a rigid robot. Their high compliance gives soft robots the potential to safely and effectively interact with obstacles, and even to use surrounding objects as aids to locomotion. Robots that embrace touch instead of avoiding it could transform applications through physical human-robot partnership. Specifically, the direct use of assistive and intelligent third-hand devices or soft supernumerary arms could seamlessly provide new capabilities to workers or the disabled. Human-robot collaboration in industry could improve efficiency, reduce cost, and increase the global competitiveness of US manufacturing.
The objective of this project is to endow soft robots with intelligence in navigating real-world environments autonomously using a hierarchical control approach from low-level functions and motion primitives to high-level locomotion tasks. The tasks to be accomplished towards this objective include a modular soft robot architecture with distributed actuation, high-density deformation sensing, embedded module-level control, and inter-module communication; control methods to achieve reliable and repeatable dynamic module responses, to optimize performance over time based on past iterations, and to provide high-level decision making by stochastic abstraction and control of the system in its environment through data-driven modeling; and motion planning and locomotion algorithms to find curvature bounded trajectories through cluttered environments, exploit contact to achieve obstacle aided locomotion, and 3-D motion primitives to operate on granular surfaces.
Related Publications:
- Santoso, Junius and Skorina, Erik H and Salerno, Marco and de Rivaz, Sébastien and Paik, Jamie and Onal, Cagdas D. "Single chamber multiple degree-of-freedom soft pneumatic actuator enabled by adjustable stiffness layers," Smart Materials and Structures, v.28, 2019.
- Qin, Yun and Wan, Zhenyu and Sun, Yinan and Skorina, Erik H. and Luo, Ming and Onal, Cagdas D.. "Design, fabrication and experimental analysis of a 3-D soft robotic snake," 2018 IEEE International Conference on Soft Robotics (RoboSoft), 2018.
- Gasoto, Renato and Macklin, Miles and Liu, Xuan and Sun, Yinan and Erleben, Kenny and Onal, Cagdas and Fu, Jie. "A Validated Physical Model For Real-Time Simulation of Soft Robotic Snakes," International Conference on Robotics and Automation, 2019.
- Liu, Xuan and Fu, Jie. "Compositional planning in Markov decision processes: Temporal abstraction meets generalized logic composition," Annual American Control Conference, 2019.
- Ornik, Melkior and Fu, Jie and Lauffer, Niklas T. and Perera, W. K. and Alshiekh, Mohammed and Ono, Masahiro and Topcu, Ufuk. "Expedited Learning in MDPs with Side Information," IEEE Conference on Decision and Control, 2018.
Sponsor:
~~~
{}{img_left}{img/NSFLogo.jpg}{alt text}{100}{100}
~~~
= Past projects:
== Anytime and scalable planning: Function approximation meets importance sampling
~~~
{}{img_left}{img/dubinstraj.jpg}{alt text}{400}{300}
Planning of nonlinear robotic systems is NP-complete. Thus, approximate solutions have been investigated, such as discretization-based ([https://en.wikipedia.org/wiki/A*_search_algorithm A\*]) and sampling based ([https://en.wikipedia.org/wiki/Rapidly-exploring_random_tree RRT\*]). We explore a different approximation scheme --- *function approximation* --- that transforms the planning problem in state space or workspace to a planning problem in a parameter space for policy function approximation. A /dimensionality reduction is achieved/ because the parameter space can be low dimensional, comparing to the state space. \n
In our preliminary work, we introduced *importance sampling* to
efficiently search for optimal feedback policy function
approximation. See the left figure for applying the sampling-based algorithm for
motion planning for a [http://planning.cs.uiuc.edu/node658.html Dubins Car-like robot] for goal reaching and
obstacle avoidance. Lines from the initial sample to the last sample upon convergence vary from the lightest to darkest grey.
The algorithm supports parallel computation and anytime
planning. Thus, it has the potential to take full advantage of
scalable parallelization computing scheme in cloud robotics and
GPU-accelerated robotics.
~~~
== A hybrid system approach to temporal logic optimal control based on automata theory
~~~
{}{img_left}{img/automata_ltl.jpg}{alt Automata and trajectory}{500}{300}
Optimal control for temporal logic specifications is hindered by the issue of scalability because the system needs to keep track of progress, i.e., a finite memory, to determine its actions. In this project, we exploit the insight that temporal-logic constrained optimal control can be formulated as a hybrid system, precisely, a system with switching between different modes triggered by the automaton translated from a linear temporal logic formula. We integrated approximate optimal control for hybrid systems into temporal logic constrained optimal control for making such methods scalable for large systems. The approach will be presented at [http://cdc2016.ieeecss.org/ IEEE CDC2016].
The left figure (above) presents a simple specification, in plain language, visit A before B and visit C before B and eventually either A or C needs to be visited. The bottom one shows the trajectory of the closed-loop linear system under the approximate optimal controller. This method opens up a new realm for scalable synthesis in formal methods.
Previously, scalable, distributed optimization methods have also been developed for probabilistic model checking and planning for Markov decision processes, see [files/papers/Fu-Han-Topcu-2015-CDC.pdf here our CDC paper in 2015].
~~~
== Game theory for reactive, learning, and active sensing robots
~~~
{}{raw}
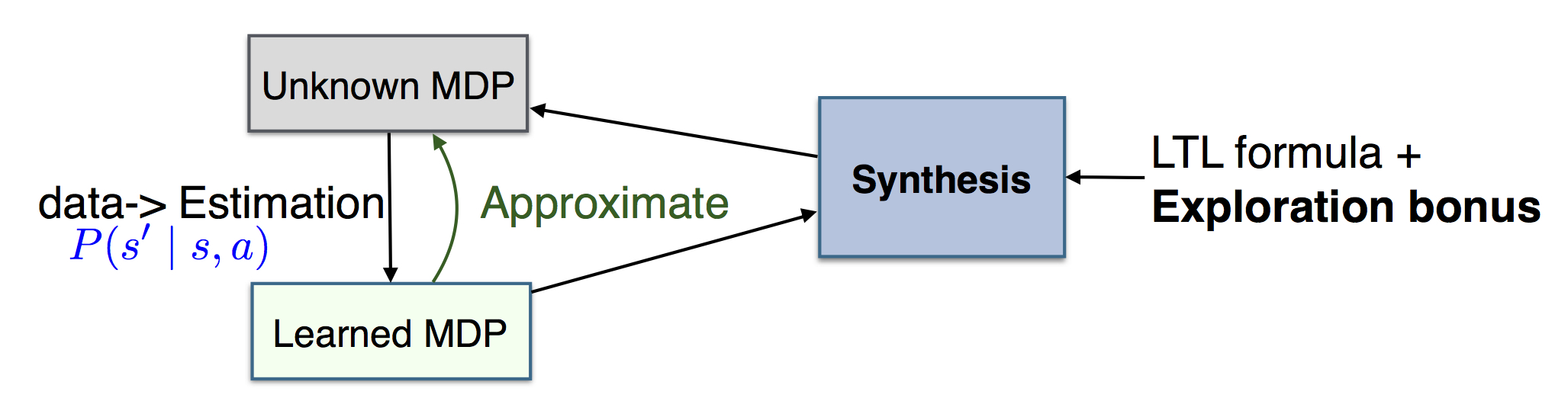 ~~~
"A reactive system is a system that responds (reacts) to external events." One of my research interests is to develop reactive and adaptive systems based on game theory and machine learning. Applications of such systems include, but are not limited to, robot surveillance tasks in the presence of uncertain and uncontrollable environment, fast-response search and rescue robot teams, and autonomous driving with limited sensing information.
[files/papers/Fu-EtAl-2013-TAC.pdf Our previous work] shows a way of integrating grammatical inference and game theoretic analysis to enable a discrete transition system to satisfy a behavior specification while interacting with an adversarial, unknown, rule-governed environment. During my post-doc, we introduce a distinguished connection between [https://en.wikipedia.org/wiki/Probably_approximately_correct_learning PAC learning] and
probabilistic model checking to synthesize a policy that is
iteratively updated based on learned information, and with convergence
guarantees of the optimal solution. Here is a [files/papers/Fu-Topcu-2014-RSS.pdf link] to our work.
~~~
{}{img_left}{img/wumpus.jpg}{alt Automata and trajectory}{700}{300}
Besides learning-based reactive systems, I am also interested in developing algorithms that allow an agent to trade computation effort with information. A game with partial information is computationally expensive to solve due to a subset construction (from partially observed game to a game with complete information).
In this [files/papers/Fu-Topcu-2016-TAC.pdf work], an active sensing method is introduced such that under partial information, the system is able to gain information and reuse its strategy synthesized using complete observation for winning a game whose state are observed partially. The further extension includes reactive systems for stochastic games and integrating sensing uncertainty into active sensing-based reactive control design.
~~~
~~~
"A reactive system is a system that responds (reacts) to external events." One of my research interests is to develop reactive and adaptive systems based on game theory and machine learning. Applications of such systems include, but are not limited to, robot surveillance tasks in the presence of uncertain and uncontrollable environment, fast-response search and rescue robot teams, and autonomous driving with limited sensing information.
[files/papers/Fu-EtAl-2013-TAC.pdf Our previous work] shows a way of integrating grammatical inference and game theoretic analysis to enable a discrete transition system to satisfy a behavior specification while interacting with an adversarial, unknown, rule-governed environment. During my post-doc, we introduce a distinguished connection between [https://en.wikipedia.org/wiki/Probably_approximately_correct_learning PAC learning] and
probabilistic model checking to synthesize a policy that is
iteratively updated based on learned information, and with convergence
guarantees of the optimal solution. Here is a [files/papers/Fu-Topcu-2014-RSS.pdf link] to our work.
~~~
{}{img_left}{img/wumpus.jpg}{alt Automata and trajectory}{700}{300}
Besides learning-based reactive systems, I am also interested in developing algorithms that allow an agent to trade computation effort with information. A game with partial information is computationally expensive to solve due to a subset construction (from partially observed game to a game with complete information).
In this [files/papers/Fu-Topcu-2016-TAC.pdf work], an active sensing method is introduced such that under partial information, the system is able to gain information and reuse its strategy synthesized using complete observation for winning a game whose state are observed partially. The further extension includes reactive systems for stochastic games and integrating sensing uncertainty into active sensing-based reactive control design.
~~~