1. Sensors
Event camera, streaming biosignals, robotics sensors, or low-power edge inputs.
2. Structured Recurrent SNN
Local recurrent microcircuits with sparse small-world routing.
3. Modulatory Feedback
Random feedback projections compress task error into low-dimensional learning signals.
4. Decision
Readout population produces classification or control decisions in real time.
Abstract
Modern AI systems rely on backpropagation, which requires dense communication, large memory movement, and global synchronization. This project explores an alternative: learning through local synaptic updates guided by low-bandwidth global signals.
We introduce a structured recurrent spiking neural network that combines locally recurrent microcircuits, sparse small-world long-range connectivity, and neuromodulatory feedback. The goal is to test whether useful credit assignment can emerge without precise gradient transport, enabling learning systems whose cost scales with activity rather than network size. This framework is designed for temporal sensing tasks such as event-based vision, streaming signal classification, and low-power edge intelligence.
Core Idea
Local recurrent computation
Each layer forms a structured microcircuit that supports temporal memory and rich dynamics through local recurrence.
Sparse small-world routing
Long-range projections create efficient information flow without dense communication or all-to-all connectivity.
Low-bandwidth learning
Random feedback pathways and modulatory populations replace full gradient propagation with compressed learning signals.
Method
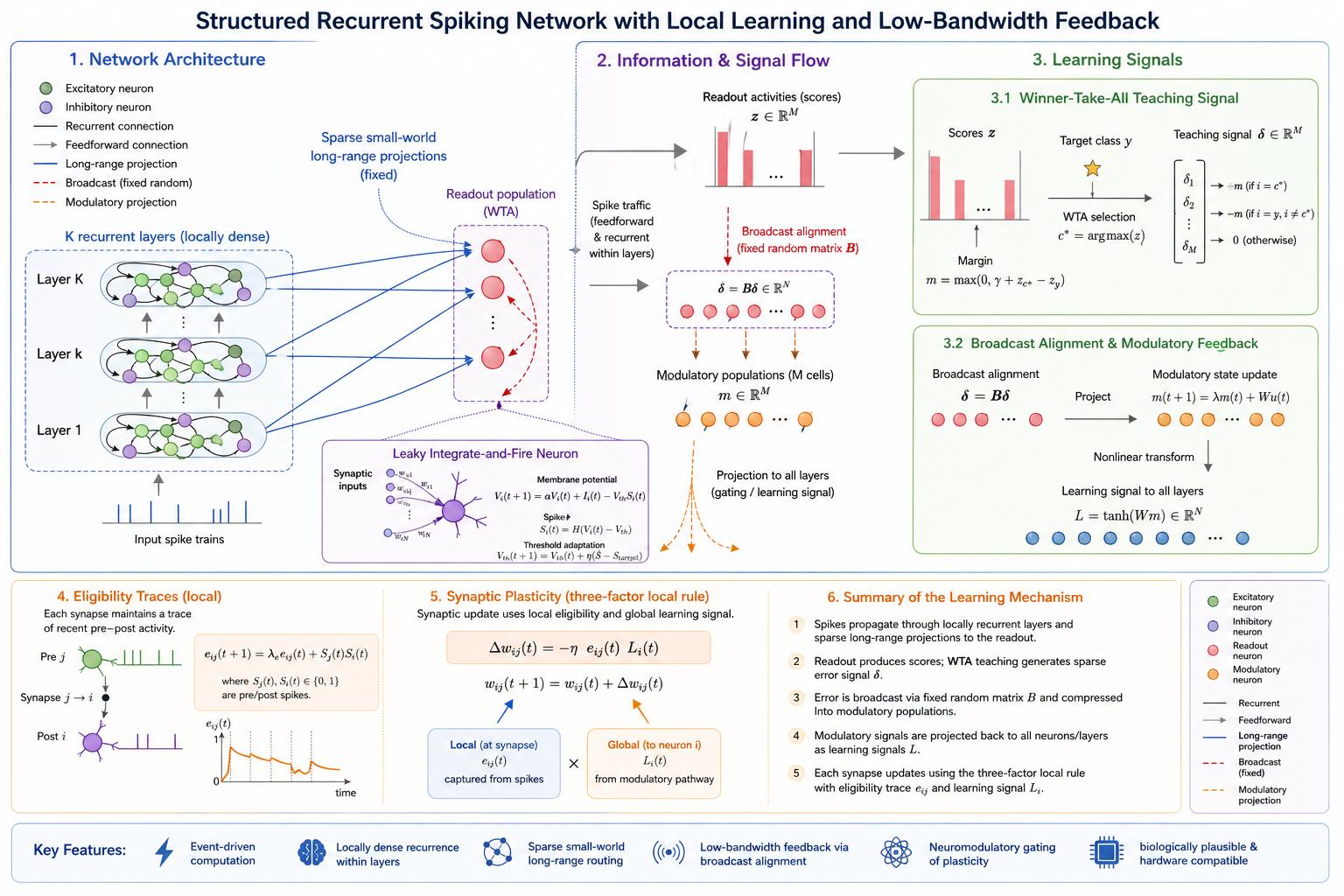
The proposed model combines structured recurrent spiking dynamics, sparse small-world routing, and low-bandwidth modulatory feedback. The key mechanisms are summarized below using the notation from the paper.
Network Architecture
The network contains $K$ stacked recurrent layers. Each layer $L_k$ forms a locally dense recurrent microcircuit, receives feedforward input from $L_{k-1}$, and sends sparse long-range projections to the readout population.
Neuron Dynamics
Neurons follow discrete-time leaky integrate-and-fire dynamics, with a slow homeostatic threshold update to stabilize firing activity in recurrent layers.
Winner-Take-All Output Teaching Signal
The readout population accumulates spike counts $z\in\mathbb{R}^C$. A sparse margin-based WTA signal provides class-level supervision without softmax normalization or gradient computation.
Broadcast Alignment and Modulatory Populations
Output errors are broadcast through fixed random matrices and compressed by low-dimensional modulatory populations. These signals gate plasticity but do not inject feedback currents into neuronal dynamics.
Eligibility Traces
Each plastic synapse stores a local eligibility trace that accumulates recent pre- and post-synaptic spike correlations and decays over time.
Synaptic Plasticity
Hidden-layer synapses are updated using a three-factor rule combining eligibility, modulatory feedback, and a local learning rate. Readout synapses use a local delta rule.
Preliminary Momentum
Initial experiments demonstrate stable local learning in structured recurrent spiking networks, supporting the feasibility of a larger proof-of-concept study.
Why It Matters
Backpropagation has powered modern AI, but its dependence on dense communication makes it poorly matched to low-power, distributed, and event-driven environments. This project targets that bottleneck directly. If successful, it could support a new class of intelligent systems that learn continuously at the edge, adapt in real time, and map naturally onto neuromorphic hardware such as Loihi-class chips.